面向移动视觉的目标检测模型级联优化
时间:2023-03-23 15:40:06 来源:柠檬阅读网 本文已影响 人 
余德亮,谭 光,李昌镐
(中山大学 智能工程学院,广东 广州 510000)
移动视觉任务在当前大量的移动设备和可穿戴设备中广泛流行使用,移动视觉任务包括道路车辆检测和监控、行人数量统计、街道导航等任务。解决移动视觉任务采用目标检测模型,当前主流的目标检测模型有着计算准确率高、计算速度快的特点,但移动设备无法支撑目标检测模型庞大的计算量。当前有3类主流工作从不同角度出发解决这一问题。第一类工作从深度卷积神经网络模型轻量化的角度出发,例如文献[1-3]。第二类工作是采用端云协同[4]的方法,例如文献[5-7]。第三类工作是在本地构建优化系统框架,例如文献[8-16]提出了DeepCache框架,采用重复区域搜索、模型检测两层级联的方式解决移动视觉任务,并利用连续视频帧存在重复区域特性减少模型计算量。但现有工作包括DeepCache的主要问题是没有设计适应场景变化的模型级联方案。
本文提出面向移动视觉的目标检测模型级联优化方案,该方案包含模型级联框架以及模型配置选择器。模型级联框架级联重复区域搜索、小模型筛选、大模型检测这3种方式,设计不同的选择方案应用于变化的移动视觉场景。模型配置选择器提取场景的变化特征信息,选择合适的模型级联框架。目标检测模型级联优化方案有两个创新点:①实现了基于掩码卷积的模型级联框架;
②设计了模型配置选择器,模型配置选择器根据场景特征信息选择合适的模型级联框架。
在移动视觉场景中,连续视频帧存在着重复区域的特性,模型级联框架利用该特性在目标检测的过程中跳过重复区域的计算,减少模型的运算时间。为实现这一功能,本文改进目标检测模型的卷积方式。模型级联框架在重复区域搜索和小模型筛选的方式中会给出重复区域的掩码信息,掩码卷积结合这一信息跳过对输入图像重复区域的卷积计算。
掩码卷积在基础卷积方式上进行改动。卷积的计算公式如式(1)所示,其中f为输入图像,h为卷积核参数,g为输出图像,*为卷积运算符号
g=f*h
(1)
为了让卷积只计算本文需要的图像区域,需要对输入图像进行掩码操作,通过掩码操作的卷积计算公式如式(2)所示,其中σ为掩码操作
g=σf*h
(2)
掩码操作后的卷积计算如图1所示,左图为进行过掩码操作的输入图像,图像中的虚线部分即进行掩码过的区域。在卷积计算中,卷积核跳过虚线部分区域的计算,同时在其对应输出区域进行填0保证后续卷积计算的有效性,从而得到右图结果。掩码卷积的设计会内嵌到小模型和大模型当中。
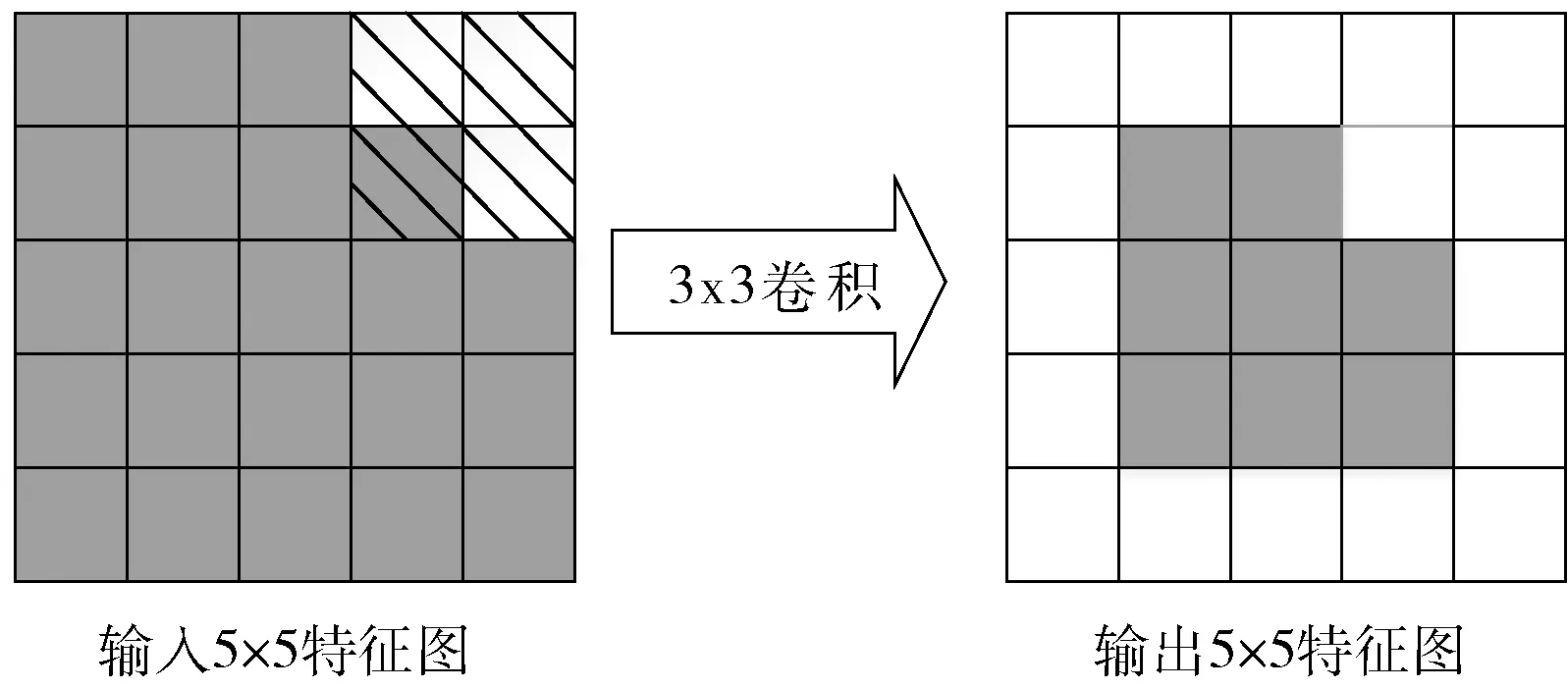
图1 掩码卷积细节
模型级联框架根据搜索算法得到的重复区域生成掩码信息输入到小模型当中,小模型根据掩码信息进行掩码卷积,得到计算结果。然后模型级联框架调低小模型的检测置信度阈值,生成更多可能是目标的区域,根据小模型检测得到的区域生成掩码信息输入到大模型进行计算,此时小模型检测得到目标的区域为非掩码区域,而其它区域为掩码区域。最后大模型对剩余非掩码区域进行计算得到结果。最终模型级联框架输出结果是大模型计算结果以及重复区域在上一帧中出现的计算结果。模型级联框架如图2所示。

图2 模型级联框架
模型级联框架为场景不同变化状态提供不同的组合方案,进一步的本文构建以神经网络为基础的模型配置选择器。模型配置选择器会提取当前场景的变化特征信息,分析并选择适合当前场景的模型级联框架。
本文设计的描述场景变化情况提取的特征信息包括:①上一帧图像的目标数量;
②前5帧的平均目标数量;
③上一帧图像中所有目标的平均位移量;
④场景的平均位移量。
对于第2个特征信息,连续图像帧存在重复区域的特性,模型配置选择器提取上一帧图像的目标数量可以对当前帧的目标数量分析有帮助,但在对当前图像帧进行检测的时候无法预先知道场景出现的目标数量,需要获取历史帧目标数量变化的情况,因此本文设计前5帧平均目标数量的特征信息。
在第3个特征信息中,模型配置选择器计算上一帧图像中所有目标的平均位移量时,需要结合上一帧和上两帧图像的目标坐标信息。对于上一帧图像中的任一目标,模型配置选择器会在上两帧图像的相同类别目标中计算交并比IOU,寻找得到最大IOU的对应目标,对于最大IOU大于0.7的对应目标,计算这两个目标中心点的差值,统计上一帧图像的目标中所有找得到对应目标的差值求平均,得到平均位移量。上一帧图像中所有目标的平均位移量NMV(x,y) 计算公式如式(3)所示,其中 (xi,yi) 代表满足条件的待匹配图像块坐标, (x′i,y′i) 代表对应的匹配块在原图像的坐标,S表示满足条件的图像块集合,N为集合S的元素数量

(3)
场景的平均位移量是根据当前帧图像和上一帧图像进行分析得到。模型配置选择器采用多方向搜索算法计算连续帧之间的场景位移信息,该算法流程如算法1所示。该方法通过对图像分块,计算相邻两帧图像块的匹配情况,不仅可以寻找连续两帧图像之间的重复区域,还可以根据重复区域计算场景的平均移动向量。在搜索算法计算得到相邻两帧图像匹配的图像块集合之后,模型配置选择器根据式(4)计算平均移动向量MV(x,y), 其中 (xi,yi) 代表满足条件的待匹配图像块坐标, (x′i,y′i) 代表对应的匹配块在原图像的坐标,S表示满足条件的图像块集合,N为集合S的元素数量

(4)
算法1:多方向搜索算法流程
(1) 初始化imagecurrent, imagepervious, mv_set={}, reuse_set={}, cluster_num=2,T;
(2) for i in N:
(3) for j in N:
(4) blockcurrent, blockpervious=FindMatchBlock(imagecurrent,imagepervious,i,j) //寻找匹配块
(5) mv=ComputeMoveVector(blockcurrent, blockpervious) //计算位移向量
(6) CollectBlock(mv_set, blockcurrent, mv) //搜集匹配块
(7) for i in direction:
(8) mv_kmeans(mv_set[i], cluster_num) //采用kmeans聚类方法根据位移向量聚类块
(9) for i in direction:
(10) for cluster in mv_set[i]:
(11) new_mv=GetMoveVector(cluster) //获得该聚类簇的平均移动向量
(12) for block in cluster:
(13) matchblock=FindNewMatchBlock(ima-gecurrent, block, new_mv) //根据新的移动向量寻找新的匹配块
(14) psnr=ComputePSNR(matchblock,block) //计算当前块和匹配块的PSNR值
(15) if psnr>T:
(16) blockcurrent∈reuse_set
(17) reuse_set 为可重用区域
搜索算法采用图像差分法时,会采用多方向搜索算法计算场景的平均移动向量,这种算法在计算场景平均移动向量时所需耗费时间很少,相对于模型计算所需用到的时间耗费可忽略不计。对于视频数据集来说,每一帧图像都是一个数据点,模型配置选择器除了对每个数据点提取上述的特征信息之外,还会分配一个模型级联框架作为标签代表当前场景下的选择方案。为了给每个数据点确定合适的目标检测框架,本文通过提取的特征信息和目标检测框架测试结果来选择最优框架,对于提取的特征信息,本文按场景变化复杂情况分成高中低3类,对应3组不同的模型组合集,每组模型组合集分别包含3种模型组合,在每个数据点分配到对应的模型组合集之后,本文选择模型组合集里面的所有模型组合对数据点进行测试,再根据目标数量和场景变化快慢再分成3组,相当于每类3组一共9组情况。数据点选择模型组合的准则在于,数据点在不同的模型组合表现的精度计算会有所不同,这与模型组合的表现力相关,当数据点包含的目标比较少的时候,模型组合表现力即使不用过高也能满足精度要求,这时候模型配置选择器会倾向选择减少模型计算力的方案,而对于数据点包含目标比较多的情况,模型配置选择器会着重采用表现力较强的方案,而减少模型计算力的方案应放在其次。基于以上准则,虽然模型配置选择器不能保证每个数据点确定的模型组合最优的,但每个数据点确定的模型组合都是较为合适的。
图3为模型级联框架和模型配置选择器在模型级联优化方案中的组合关系,在该优化方案中,前5帧图像会直接采用大模型进行检测,在之后的图像帧处理中,图像缓存器会缓存历史采集的图像信息,模型配置选择器会根据当前采集的图像和图像缓存器的信息提取当前场景的特征信息,并根据特征信息选择合适的模型级联框架配置,模型级联框架根据模型配置选择器提供的配置信息选择搜索算法和模型组合,并对当前帧图像进行检测,得到最终输出结果。
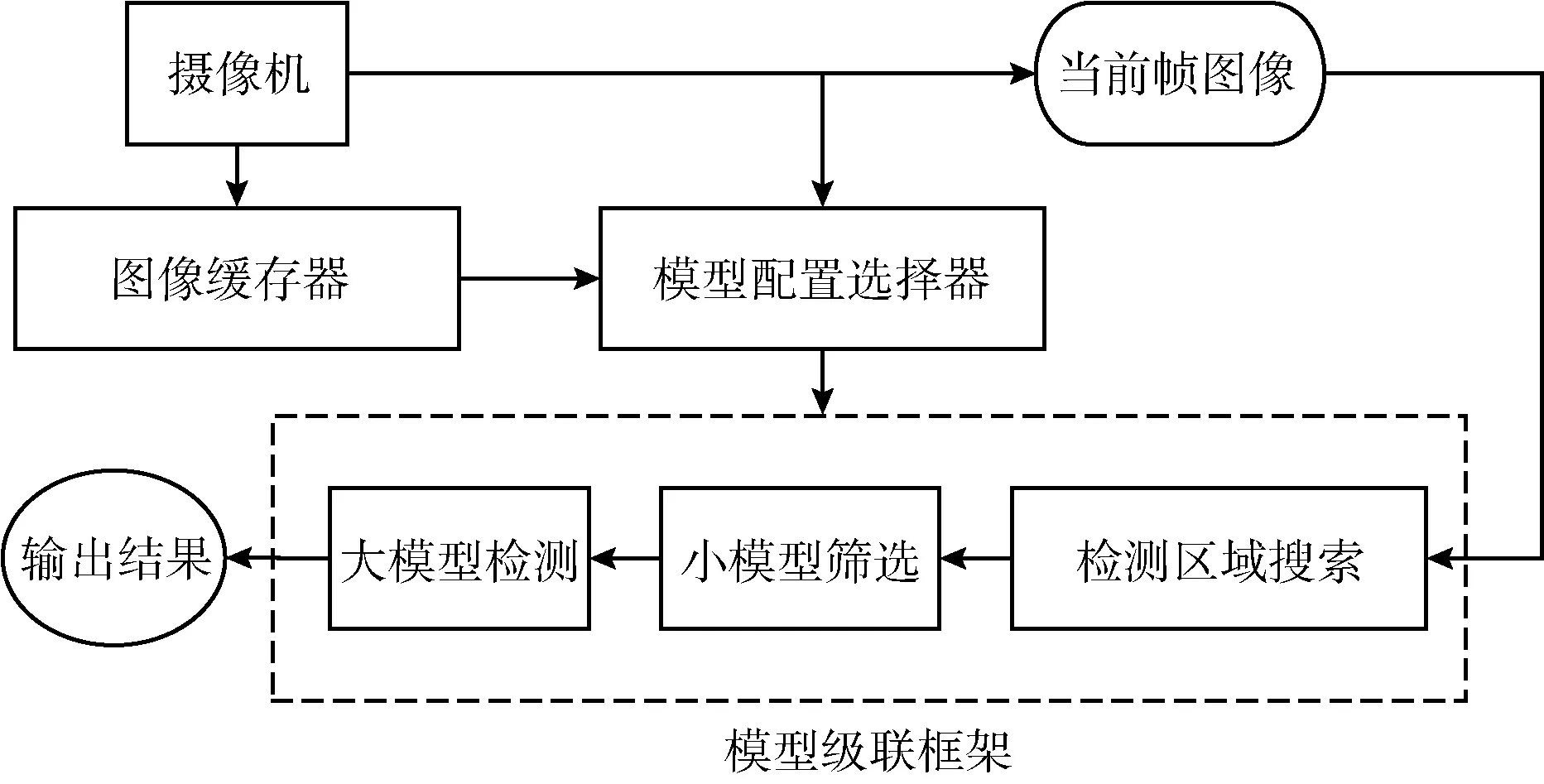
图3 模型级联框架和模型配置选择器的组合关系
本文实验在电脑上进行,CPU型号是i7-8700,操作系统是ubuntu18.04。实验代码以C++语言基础,借助ncnn框架设计实现,ncnn框架是面向移动视觉应用部署深度学习的框架。本文实验为模拟移动设备的实际运行情况,因此主要在CPU上运行实验。实验数据采用了KITTI、UA-DETRAC、MOT16、OTB这4种数据集进行挑选组合。其中挑选的数据集先按场景数量和变化情况分成三大类,第一类数据集包含KITTI训练数据集中的序号12、17,测试数据集的序号15的片段499-644,UA-DETRAC数据集中的序号MVI_40992和OTB数据集的subway;
第二类数据集包含KITTI训练数据集中的序号5、8、10、16、18,以及测试数据集中的序号14的片段428-595和684-849、15的片段279-532和645-700、16;
第三类数据集包含KITTI训练数据集中的序号11、13,MOT16数据中的序号7、14,UA-DETRAC数据集中的序号MVI_40131。
3.1 模型组合
在本文实验中,采用了一共9种目标检测模型级联框架,采用了f1-score的计算方法,模型级联框架的测试精度和计算时间是在KITTI数据集上测试得到,这里测试的KITTI数据集是所有视频连续帧组成的图像集合,计算结果见表1。
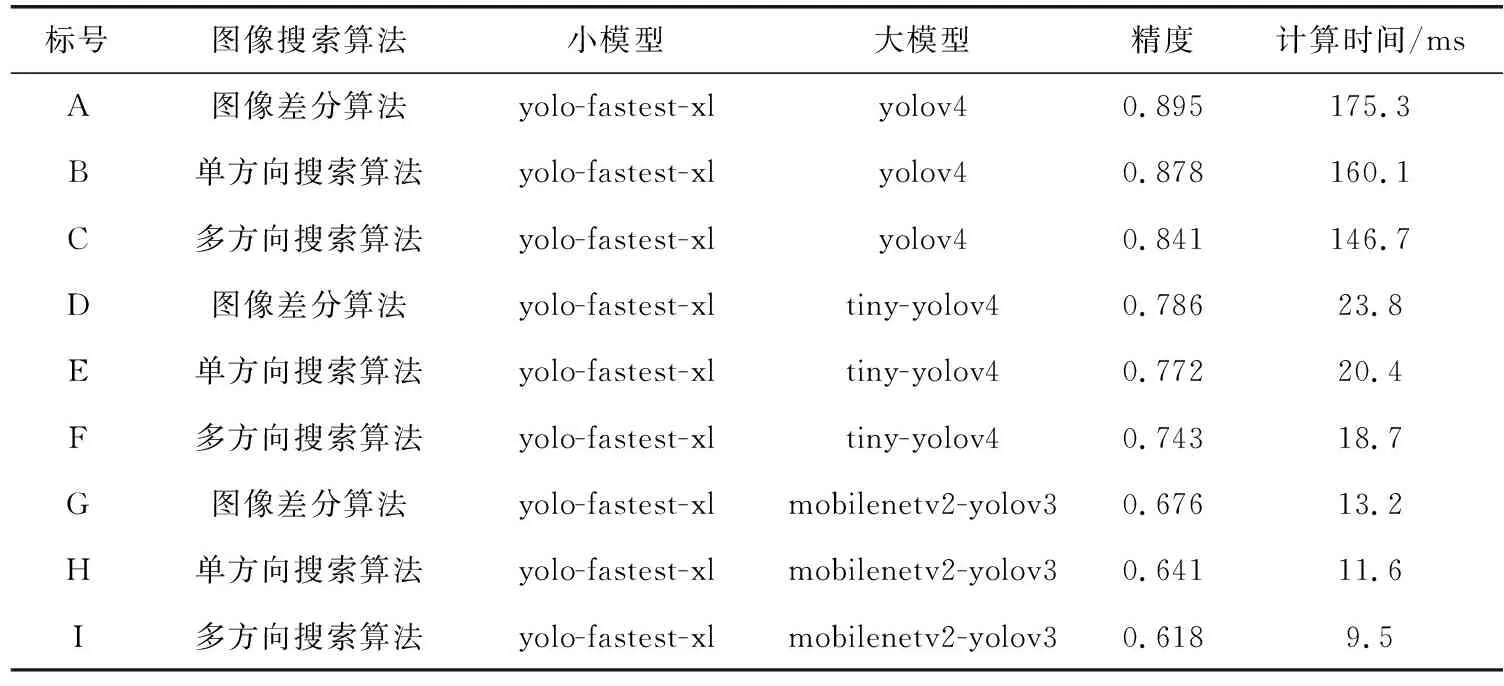
表1 不同模型级联框架在KITTI数据集中的计算精度和计算时间
图像搜索算法采用了3种方法,图像差分算法、单方向搜索算法[13]和多方向搜索算法。图像差分算法搜索重复区域数量最少,单方向搜索算法搜索重复区域数量其次,多方向搜索算法搜索重复区域数量最多。当搜索重复区域较多时,模型级联框架花费的计算时间就会越少,但与此同时模型精度会较低,而搜索重复区域较少的时候,模型精度会比较高,但需要花费的计算时间较多。
小模型只选择了轻量化模型yolo-fastest-xl这一种方案,这是因为小模型的作用在于选择搜索算法筛选下来的非重复区域中是否有感兴趣区域,小模型尽可能选择目标,而目标检测结果可以由大模型来保证。在本文的实验过程中发现选择满足条件的不同的小模型去搭配不同的模型组合是对于整体的框架精度和计算时间没有过多影响。
大模型选择了3种不同精度和计算时间的模型,其中yolov4精度最高,但在模型计算中耗费时间最长,tiny-yolov4和mobilenetv2-yolov3相比于yolov4虽达不到那么高的精度,但在计算时间上花费远小于yolov4,tiny-yolov4相比mobilenetv2-yolov3需要花费多一些计算时间,但精度比mobilenetv2-yolov3高一些。大模型判断小模型筛选出来的目标是否准确,需要有一定的精度要求,但由于需要应用的场景不同,所以在大模型上会有不同的模型选择。表2是yolov4、tiny-yolov4和mobilenetv2-yolov3在KITTI数据集上的计算精度和计算时间,模型组合C和yolov4比较得到精度减少6.3%,时间减少45%;
模型组合F和tiny-yolov4比较得到精度减少6.9%,时间减少52%;
模型组合I和mobilenetv2-yolov3比较得到精度减少7.7%,时间减少54%。对比实验结果可以发现无论是哪种模型应用于模型级联框架,都可以实现精度损失较少的情况下计算时间大幅度减少的优化方案。本文设计的模型级联框架在精度上会有些许差距,这是因为在搜索算法的时候会带来一些精度减少,用小模型进行筛选的时候也会有些许的误差,但总的来说,在精度减少少量的情况下模型级联框架可以减少大量的计算时间和模型计算量。

表2 不同模型在KITTI上的测试精度和计算时间
表3给出了主流模型和对应配置的模型级联框架占用内存量的对比,其中yolov4为大模型的级联模型框架采用组合C作对比,tiny-yolov4为大模型的级联模型框架采用模型F作对比,mobilenetv2-yolov3为大模型的级联模型框架采用模型I作对比。可以看到模型级联的方式搭建的框架对比同等主流模型消耗的内存量并不多,而当前本文所选择的主流模型都是可借助ncnn部署在移动端上进行实际运行的,本文设计的模型级联框架也是借助ncnn框架实现的,也可方便部署在移动端上实现相应功能。
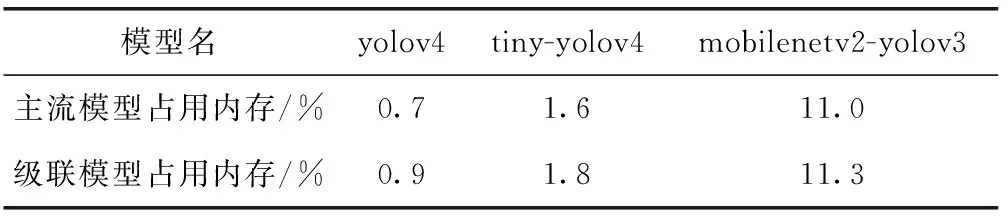
表3 主流模型和级联模型占用内存量对比
3.2 模型配置选择器
本文实验搭建一个模型配置选择器,在实时检测的时候可以提取当前视频图像帧信息选择合适的模型级联框架。用于框架选择器训练的训练数据包含近5000张图像,每个图像提取4种特征信息,即①上一帧图像的目标数量N;
②前5帧的平均目标数量EN;
③上一帧图像中所有目标的平均位移量NMV(x,y);
④场景的平均位移量MV(x,y), 由于位移量由向量表示所以一共提取的特征点数量为6个,输出类别有9种,对应9个模型级联框架,数据集划分为9份训练集和一份测试集,并进行交叉验证。模型配置选择器需满足计算速度快,内存占用少,易于训练等特点,因此本文选择神经网络构建模型配置选择器,模型配置选择器构建两层线性层,每层包含50个神经元,每层输出之后采用relu作为激活层,学习器采用adam学习器,学习率为0.01,采用20个epoch,每个epoch抽取500个数据点进行训练,训练和测试的精度结果如图4所示,其中x代表epoch,y代表精度,没有采用更大的epoch是因为模型训练已经收敛,防止过拟合情况出现。

图4 模型配置选择器训练和测试结果
训练得到的模型配置选择器在训练集的精度为0.95,测试集的精度为0.85,由图4的结果可以看到模型没有出现过拟合现象,说明这种方法训练得到的模型配置选择器具有一定的选择能力。
3.3 模型组合选择测试表现情况
为了体现模型选择的合理性和优势性,本文从测试集取出3类场景数据集,并根据模型配置选择器所选的模型在提取的数据的测试精度和所需计算时间进行分析。
第一个连续视频帧数据集是KITTI测试数据集15中的片段499-644(后面简称kitti_test15),包含145张图片,每张图片包含4~6个目标,采集该数据集的摄像头处于静止状态,场景中目标移动缓慢。对于该数据集,模型配置选择器选择模型组合G进行检测,本文同时取模型组合A-F对数据集进行检测,得到的模型精度和模型计算时间如图5和图6所示。
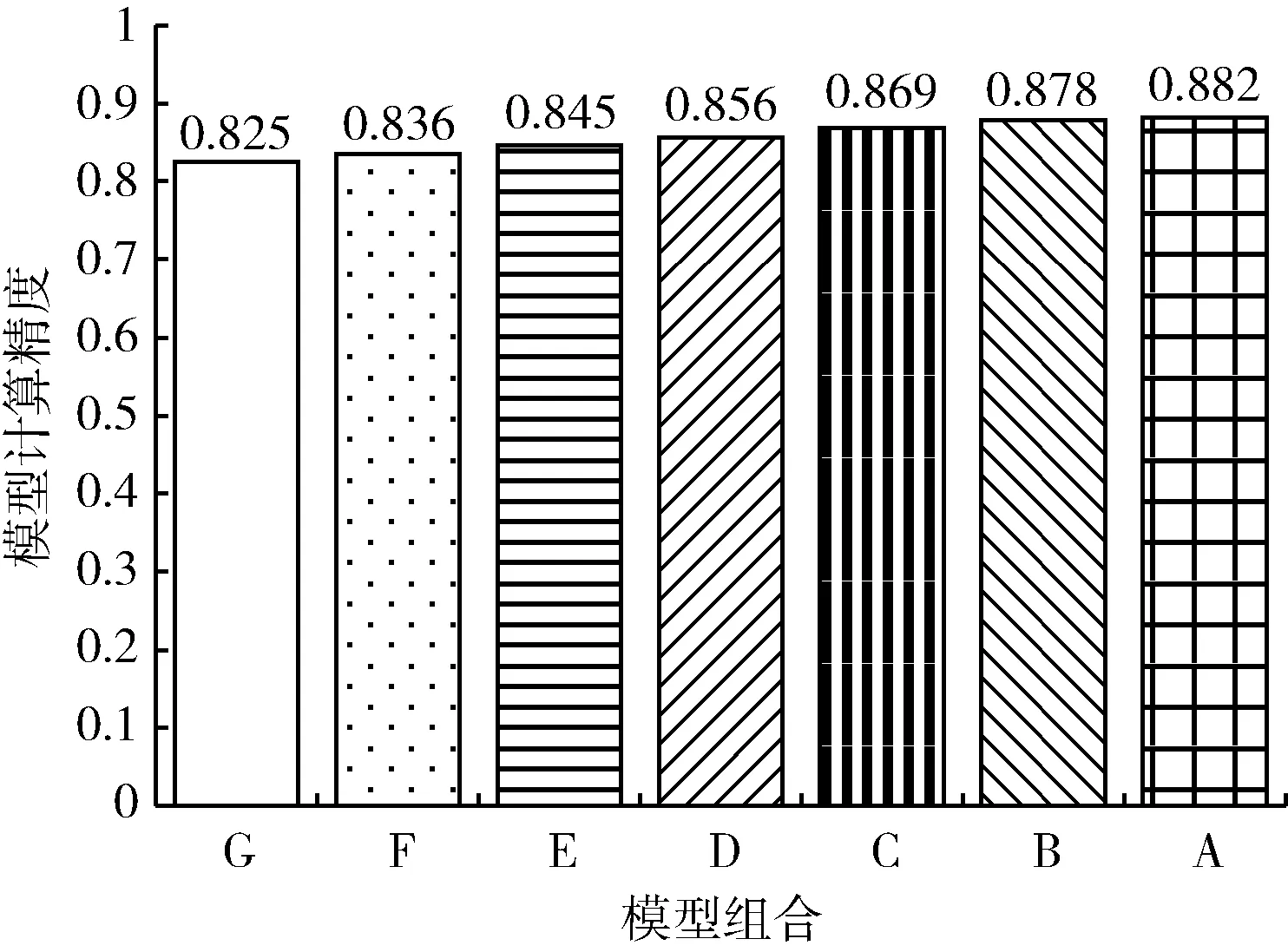
图5 模型组合A-G在数据集kitti_test15上的测试精度
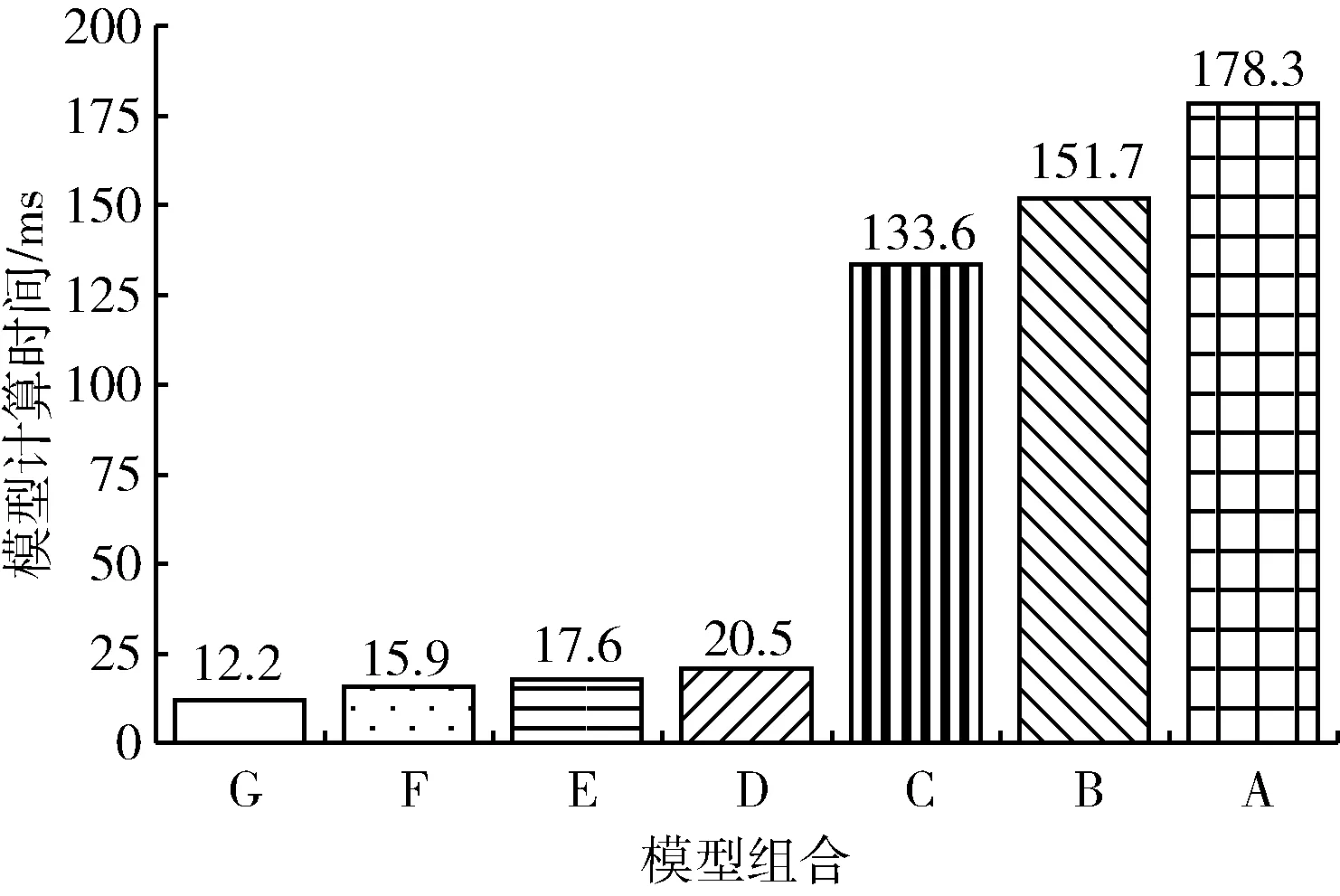
图6 模型组合A-G在数据集kitti_test15上的计算时间
从图5和图6中可以看到,选择模型组合G和模型组合A-F进行检测该数据集得到的精度差别不大,最大的差别即模型组合G和模型组合A的精度差为6%,而模型计算时间节省了166 ms。模型组合G在KITTI数据集上测试的精度仅有0.68是因为KITTI包含目标数量多,场景变化大的数据,在这种情况下模型组合G是不具备优势的,而在数据集kitti_test15中目标数量少,场景变化缓慢,这个时候模型组合G能在花费较少计算时间的情况下获得较高精度。图7为当前帧图像即待检测图像,标注即模型组合最终的检测结果,结合图7可以看到场景变化缓慢,移动数量也较少,这时候采用模型组合G同样可以得到较高的精度。

图7 数据集kitti_test15的例子中当前帧图像检测情况
第二个连续视频帧数据集是KITTI测试数据集14的428-595片段(后面简称kitti_test14),包含168张图片,每张图片包含8~10个目标,采集该数据集的摄像头处于缓慢移动状态,场景中目标移动平缓。对于该数据集,模型配置选择器选择模型组合E进行检测,本文取模型组合A-D对数据集进行检测,得到的模型精度和模型计算时间如图8和图9所示。

图8 模型组合A-E在数据集kitti_test14上的测试精度

图9 模型组合A-E在数据集kitti_test14上的计算时间
从图8和图9中可以看到,选择模型组合E和模型组合A-D进行检测该数据集中得到的精度差别较少,最大的差别即模型组合E和模型组合A的精度差为7%,而模型计算时间节省了159 ms。模型组合E在KITTI数据集上测试的精度为0.77,但它比模型组合G-I相比优势在变动的场景和目标数量较多的情况有一定的适应性。图10为当前帧图像也即待检测图像,标注即模型组合最终的检测结果,结合图10可以看到场景变化对比第一组数据较快,大部分目标在移动,场景处于不断变化的状态,这时候采用模型组合E能够保证精度较少的情况下节省更多计算时间。

图10 数据集kitti_test14的例子中当前帧图像信息
第3个连续视频帧数据集是第3类数据集UA-DETRAC中序号为MVI_40131的数据集,包含323张图片,每张图片包含至少15个目标,采集该数据集的摄像头处于较快的移动状态,场景中目标移动较快,场景变化复杂。对于该数据集,模型配置选择器选择模型组合C进行检测,本文同时取模型组合D-I对数据集进行检测,得到的模型精度如图11所示。

图11 模型组合C-I在数据集MVI_40131上的测试精度
从图11可以看到,选择模型组合E和模型组合D-I进行检测该数据集中得到的精度差别较大,从D开始精度差别达到了12%,而最高精度差在对比E和I得到为22%。图12为当前帧图像也即待检测图像,标注即模型组合最终的检测结果,对于这组数据集,场景中的物体数量多,移动速度快,处于较为复杂的情况,低精度的模型组合会产生较大的精度损失,因此模型配置选择器更关注高精度模型以满足需求而非减少计算时间。

图12 数据集MVI_40131的例子中当前帧图像信息
本文设计的模型级联优化方案解决了目标检测模型如何适应不同场景变化情况。模型级联框架对比通用的目标检测模型可以在精度损失减少6%~8%的情况下,计算时间减少40%~55%,而通过模型配置选择器的设计本文可以适应不同变化情况的场景并针对性的选择合适的模型组合,在场景变化较平缓的情况模型配置选择器可以选择模型精度损失不大,但计算时间较快的模型组合,在场景变化较快的情况下模型配置选择器可以选择能够满足精度要求的模型。本文的设计仍存在一定局限性,一是假设内存足够使用,没有进一步考虑实际内存使用情况,二是本文的模型配置选择器没有实现在线学习的策略,可加入在线学习的方式适应更多的场景变化情况,使得模型配置选择器更具鲁棒性。
猜你喜欢 选择器级联框架 铀浓缩厂级联系统核安全分析核安全(2022年3期)2022-06-29框架小资CHIC!ELEGANCE(2022年1期)2022-01-11广义框架的不相交性数学物理学报(2020年3期)2020-07-2774151在数据选择和组合逻辑电路中的灵活应用科学与财富(2019年19期)2019-12-11—— “T”级联">富集中间组分同位素的级联—— “T”级联同位素(2019年1期)2019-03-14DIV+CSS网页布局初探数码世界(2018年5期)2018-06-04深入理解CSS3结构伪类选择器软件工程(2018年3期)2018-05-15基于级联MUSIC的面阵中的二维DOA估计算法系统工程与电子技术(2016年2期)2016-04-16关于原点对称的不规则Gabor框架的构造燕山大学学报(2015年4期)2015-12-25多组分同位素分离中不同级联的比较研究原子能科学技术(2015年12期)2015-07-07








