基于生态环境信息的数据仓库模型构建
时间:2023-01-18 19:45:12 来源:柠檬阅读网 本文已影响 人 
谢颖斯
(广东省环境科学研究院,广东 广州 510000)
生态环境信息化是当今环境保护的重要手段,也是中国政府信息化建设的关键[1]。自生态环境信息化工作开展以来,全国各级环保部门先后就不同生态环境业务建设信息系统,推动信息公开,在提高环保政务服务水平的同时,接受社会公众监督。但在信息化工作逐步推进的过程中,因欠缺系统统筹规划,各部门之间缺乏充分的沟通与交流,不同业务的信息系统独立、分散,甚至重复建设[2]。由于没有制定统一的建设标准,导致各类业务数据相互割裂、质量参差,长此以来使得大量数据可利用价值低下,不利于数据的后续更新与长远开发利用,造成资源浪费[3-4]。
随着“大数据”理念及相关技术的普及,国务院也非常重视其在政务信息化建设中的作用和两者相互促进发展的成效[5],相关部门就各领域颁布多项大数据治理政策文件,大数据治理发展环境日益完善[6]。生态环境作为与民众息息相关的一部分,也需建设智能、集成的生态环境大数据资源中心,进一步提升对环境污染统一监测、环保业务统一监管和数据分析应用的能力[7]。因此,建立一套长效的生态环境数据整合与开发利用的治理机制显得尤为重要[8]。而这首要的基础,是要基于生态环境数据的特点,打通每个业务系统之间的壁垒并彼此建立联系,将这些“信息孤岛”连成一体,建立专门集成储存生态环境信息的数据仓库。
1.1 数据种类多、规模庞大
生态环境业务种类多,各信息系统中集合了污染源监管、环境质量监测、环境信用许可、环境应急管理等不同方面与类型的信息,涉及水、大气、土壤、噪声、辐射等方面。除了以污染源名称、地理坐标、污染源总量为典型的结构化数据外,还包含了各类业务申报和审批文档、监测视频、现场图片等非结构化数据。大部分业务持续运作,数据持续更新,数据体量持续增大。
1.2 数据标准不统一、质量不高
不同业务系统之间建设标准不同,从数据库选型、运行环境、数据模型,到字段命名、字段类型、数据验证等,都没有统一的标准,基本数据字典目录如行政区划、国民经济行业分类、污染物种类等采用过时数据或非官方标准目录的情况非常常见。大部分系统在日常前端数据录入时没有做好数据校验,相当一部分异常、无效、重复、不完整的数据进入系统数据库,更有一部分使用范围小、更新频率低的系统在建设时从简,对数据的处理直接采用“收集—展示”方式,没有对数据库进行严谨的设计。
1.3 业务实体对象重叠,数据关联性差
多数信息系统的作用皆为有空间属性的实体业务对象(各行政区、流域、污染源等)在特定时间点的业务流程记录或信息归档,各系统的实体业务对象基本存在相互交叉、重叠的情况。但由于各业务系统分散建设,系统间数据呈碎片化,数据除了在自身所在系统内,没有可分析利用的空间,多业务联合分析统计的难度大增。结合前述两点,海量数据以离散、毫无关联的方式保存于各个数据库中,数据价值大打折扣,加上“僵尸系统”和“失效数据”的大量存在,造成了资源的极大损失。
数据仓库是一个面向主题的、集成的、不可更新的、随时间不断变化的数据集合。与存储操作性数据的传统业务系统数据库不同,它侧重于数据分析与决策支持。生态环境信息数据仓库基础建设过程主要如下。
2.1 信息探究与标准建立
信息探究关键在于2个方面:一是梳理业务逻辑与流程,界定主要分析维度;
二是理清各业务系统里的数据状况,包括业务系统数据库模型设计特点、各数据表以及每个字段的含义等,确定进入数据仓库的内容和数据入仓标准与策略。
同时,正确参照国家现有的《环境信息元数据规范》,遵循共享性、唯一性、稳定性、可扩展性、前瞻性、可行性原则建立数据标准。对行政区划代码、国民经济行业分类、污染物名录等建立唯一的公共字典目录,并与各业务系统自身的字典目录建立映射,为多业务联动提供前提。
2.2 建立数据模型
根据生态环境业务数据的特点,构建“实体—时间—事件”模型,如图1所示。
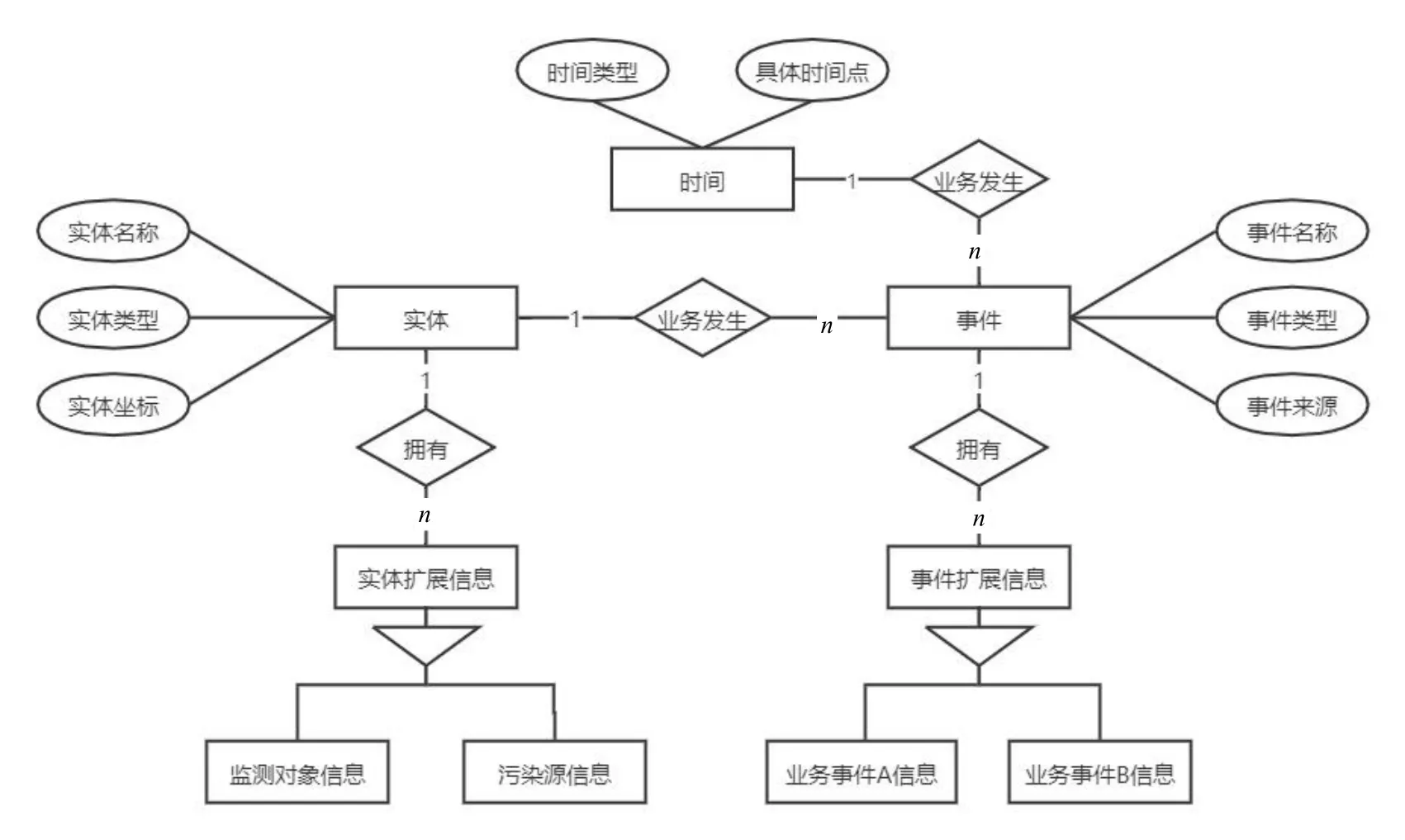
图1 “实体—时间—事件”模型ER图
“实体”指具有空间属性,且有业务管理或统计需求的业务单元,按照实体之间的空间包含关系,可以确定其层级结构并分类。由于大多数实体涉及多个业务,因此在构建实体关系结构时引入“主数据”概念。实体关系结构示例如图2所示,实线表示实体的从属关系,由实体数据的业务关系与地理坐标信息确定;
虚线表示相等关系,需要不同业务的同类实体数据比对后确定,如图中的4个固定污染源就都表示相同的业务单元。这种定义实体关系的方法,纵向看同时兼容了多种层级关系,横向看避免了复杂耗时的实体去重合并工作,而且还能由多个业务系统来对实体数据进行查漏补缺,并保留各业务下侧重不同的实体扩展信息,还能掌握实体参与各业务期间改名、易地的情况。
“时间”是实体业务对象在具体业务发生时的重要标记,根据各业务发生频率可分为年、季度、月、日、小时等多个类别。
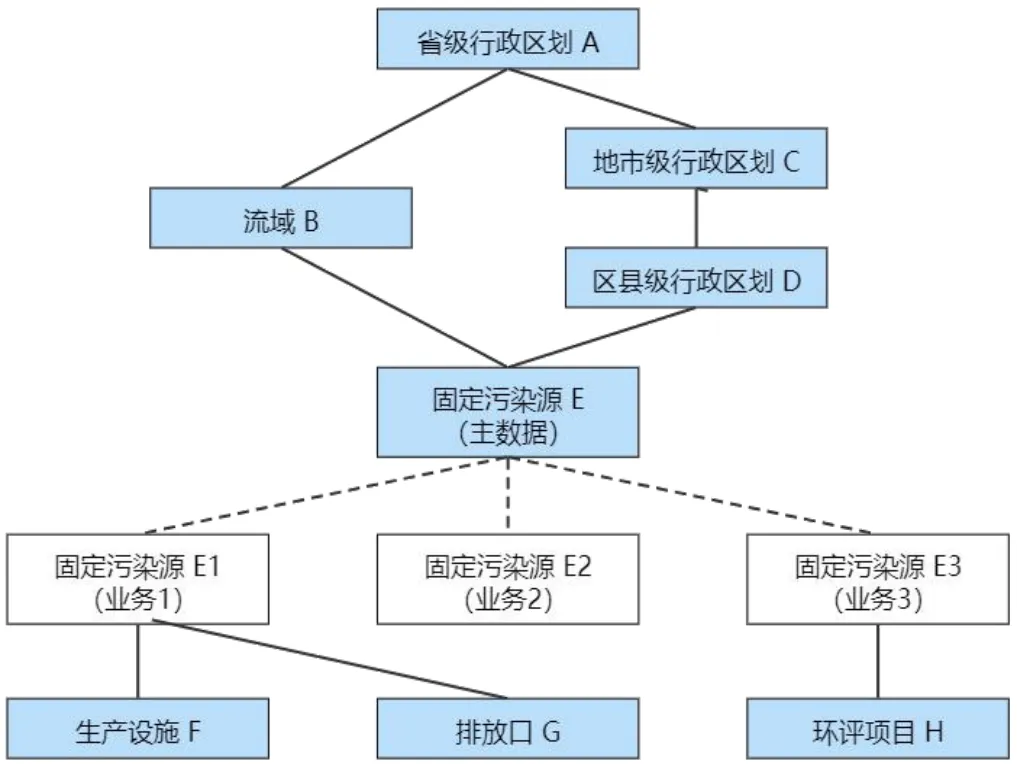
图2 实体关系结构示例
“事件”即实体在特定时间内发生的业务内容,如某排污单位的排污许可证审批或某空气质量监测点监测一次空气质量,都可以作为事件看待。事件可按生态环境核心业务种类、业务负责部门等分别进行分类。
“实体—时间—事件”模型的建立,也定义了生态环境信息的3个基本维度,如图3所示,除了能适应现有业务,也能兼容未来新增业务的接入。

图3 环境信息的3个基本维度
2.3 数据仓库分层架构
建立数据分层模型,对生态环境数据进行归纳整理。这里将数据仓库分为3层:ODS层(操作性数据层)、DW层(数据仓库层)和DM层(数据集市层)[9],设计合适的ETL(抽取—转换—加载)过程,将各业务数据库的数据经过“加工”后加载到数据仓库或数据集市中。数据从业务数据库到实际应用的流向示意图如图4所示,实际工作中需建立自动化的调度策略,用于定期有序执行ETL作业流程,以保证数据仓库的时效性。
ODS层是直接对接各个业务数据库的一层,是数据源与数据仓库之间的一个隔离,其数据库结构与业务数据库基本保持一致。数据源中的数据经过筛选,去除无效、异常、重复的部分后装入本层。每个业务所用字典目录与数据仓库公共字典目录的映射也于本层建立。
DW层为整个数据仓库的核心部分,上述数据模型于本层实装。ODS层中的数据按照所建立的数据模型重构后加载到本层。DW层的数据通常只允许增加,不允许修改或删除,实际过程中也需要定期对本层数据进行质量评审,以保证数据仓库的准确性。
DM层中的各个数据库用于存储基于数据仓库中的整合数据,根据特定需求汇总成某一专题的数据。每一个数据集市都可以看作是数据仓库的一个子集,它一般是面向特定的部门、业务或主题。
数据集市中的专题数据,可直接用于构建专题。由于数据最终直接来源于现有业务数据库,使得构建应用时省去了数据收集等步骤,避免了重复建设业务系统的弊端,也保证了数据与现有业务历史数据的一致性。同时,各业务的数据也能够按需进行关联分析,大大提高了现有数据资源的可用性与价值。
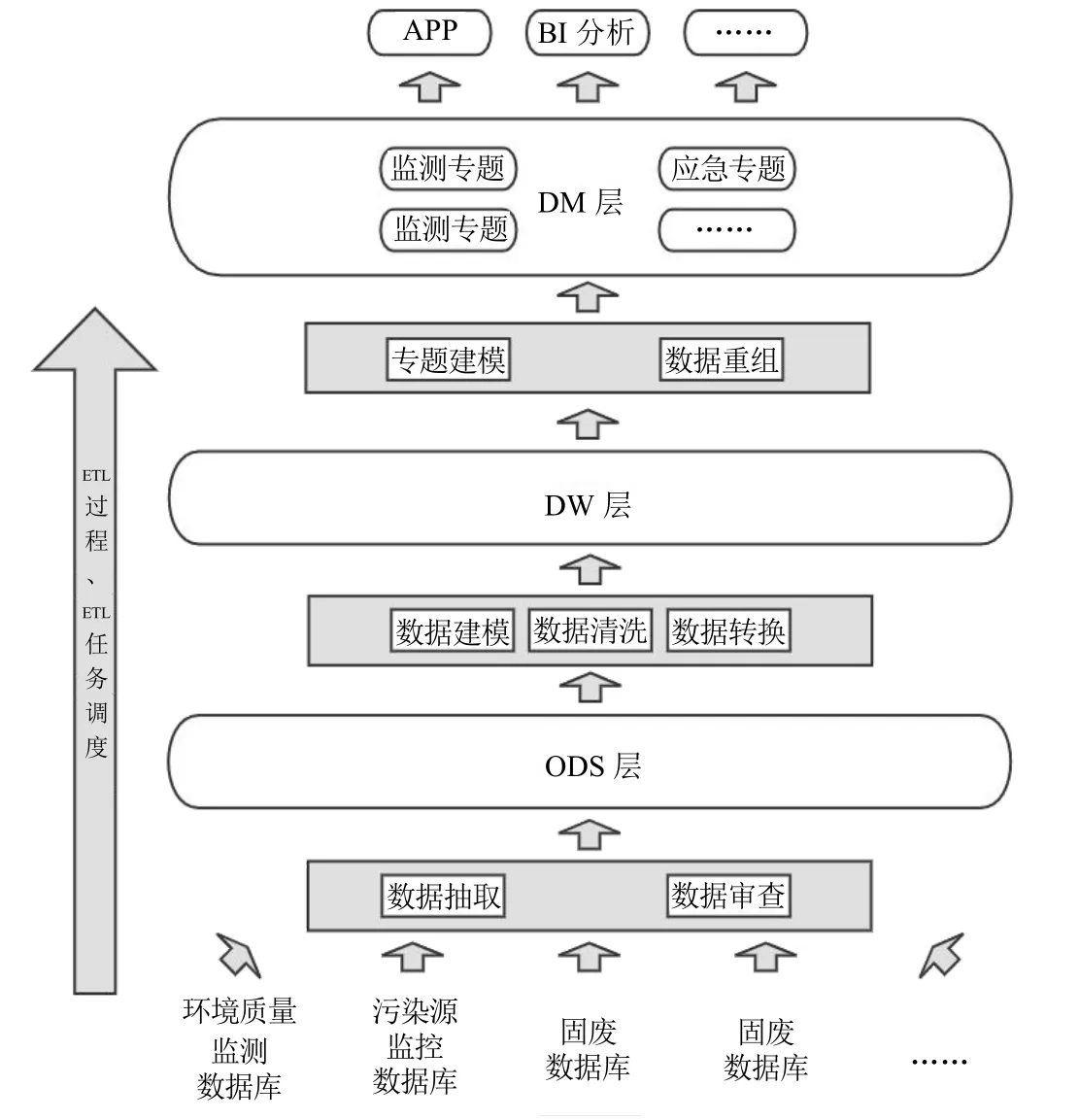
图4 数据分层及过程策略
生态环境信息数据仓库的构建,提供面向应用分析的集成化数据存储环境,为解决生态环境数据现状问题提供了整合方法与思路。后续可基于此快速构建生态环境管理专题库和应用库,并结合数据挖掘等技术,有效提高生态环境信息资源的利用价值和效率,进一步提升对生态环境业务综合管理、智能分析应用以及综合决策等信息系统建设的支撑能力。
然而,现阶段生态环境数据治理大部分还处于重点业务数据资源的基础性治理阶段,业务数据尚未完整汇聚整合,多级数据共享通道有待全面打通,数据资产构建仍需进一步体系化。因此,如何利用生态环境信息数据仓库技术结合生态环境历史数据和实时数据为智慧环保提供数据服务支撑,还需要进一步的探索。
猜你喜欢 数据仓库实体数据库 基于数据仓库的数据倾斜解决方案研究电子乐园·下旬刊(2021年3期)2021-02-08前海自贸区:金融服务实体中国外汇(2019年18期)2019-11-25实体书店步入复兴期?当代陕西(2019年5期)2019-03-21两会进行时:紧扣实体经济“钉钉子”领导决策信息(2017年9期)2017-05-04振兴实体经济地方如何“钉钉子”领导决策信息(2017年9期)2017-05-04数据库财经(2017年2期)2017-03-10探析电力系统调度中数据仓库技术的应用山东工业技术(2016年15期)2016-12-01数据仓库系统设计与实现国外科技新书评介(2016年8期)2016-11-16数据库财经(2016年15期)2016-06-03数据库财经(2016年3期)2016-03-07







