古籍文献知识组织由静态检索向动态表征趋向的实证检验*
时间:2023-04-15 08:00:06 来源:柠檬阅读网 本文已影响 人 
于蓓莉 刘 蕾 周文杰
(1.成都航空职业技术学院 四川成都 610100)
(2.西北师范大学商学院 甘肃兰州 730070)
最近数年来,在政策引导和学术引领的双重作用下,我国古籍文献数字化进程显著加速,卷帙浩繁的优秀典籍借助于OCR、自然语言处理等先进技术,不断创新存储与呈现方式[1-3],有效提升了服务效率[4-6],为开掘古籍文献中蕴含的优秀传统文化成分提供了极大便利。
对于图档博等古籍文献的管理机构来说,适应数字化时代的需求[7],对实现古籍文献序化整理由文献单元的静态检索向知识单元的动态表征的转型发展,具有重要的理论意义和实践价值。在前序研究中,本研究团队对传统分类法在古籍文献管理中应用的肇始进行了回顾,并深入评析了分类法对于古籍文献管理的贡献及局限性,并通过回顾主题法、聚类分析、关联规则等在文献管理中的应用历程,对着眼于内容挖掘的知识单元古籍文献序化整理的进展进行了深入剖析。在上述工作的基础上,本团队将科学哲学家波普尔的“世界3”归结为古籍文献知识组织的理论基础[8],从而在理论上论证了古籍文献由静态检索走向动态表征的可能性和必然性。
立足于前序研究,已从理论上对古籍文献序化整理由文献单元的静态检索向知识单元的动态表征的路向进行了充分论证,本文的目标是应用实际的古籍文献语料,通过使用自然语言处理等方法和工具,对古籍文献知识组织中的若干实践问题展开探索,以期支撑前序研究所提出的理论路向,并对后续研究的深入开展奠定基础。
古籍文献知识组织的基本目标,是通过对古籍文献中知识要素的序化整理,有效揭示古籍文献的内容结构,从而提升古籍文献的阅读效率[9]。在前序研究中,本团队已针对数字化文献的内容结构表征问题展开了一系列研究,以期为读者提供有效的辅助阅读工具,从而提高读者的阅读效率,并促进读者在阅读中获得积极的阅读体验。前序研究的结果,为本研究展开古籍文献知识组织的探索奠定了基础。
对古籍文献中加以序化整理的意义,是帮助用户以有限的分析能力“消化”数量越来越庞大的数字化古籍文献。显然,只有以高效率的数字信息分析效率为支撑,用户面对海量的数字化古籍文献时才不至于迷失其中[10]。
为此,面对古籍文献展开知识组织的首要难题,是能否提供有效辅助工具,帮助用户在结构化的古籍文献中获得有价值的阅读线索。
基于此,团队于2011 年以大学生为被试,通过单因素前后测对照组设计,检验了词频分布辅助工具对于读者阅读数字化文献的帮助作用。前序研究中,本团队通过使用AntConc 软件对实验文本进行词频统计及词分布的可视化,为读者提供条形码(见图1),其中的竖线表示特定词语在实验文本中分布情况。

图1 词频分布的条形码
在对文本进行了词频分析且制作了词频分布“条形码”的基础上,本团队对照数字信息分析辅助工具有效性实验(见表1)程序,对有辅助工具帮助读者阅读的效果进行了实验研究。

表1 数字信息分析辅助工具有效性实验各变量及处理措施一览[13]
研究结果表明,虽然高频词表对被试完成浏览型数字信息分析任务的效率无显著影响,但高频词表的可视化呈现对被试完成浏览型数字信息分析任务的效率有显著影响。也就是说,在数字化文本的阅读中,应用辅助性工具(即本文所述的“条形码”)可以有效提升读者的信息分析效率,这与现有相关文献的发现一致[11-12]。
这一研究结果清晰地表明,基于词频的可视化呈现,可以有效促进读者对于数字文献的阅读效率。由此也说明,词频分析及其可视化是对古籍文献加以知识组织的重要基础性指标[13]。
与上述研究相匹配,本团队还针对数字化信息资源阅读中,如何通过有效的知识组织方法帮助读者获得积极的阅读体验展开了研究(具体实验程序见表2)。

表2 数字信息分析中用户积极体验实验各变量及处理措施一览[14]
研究结果表明,借助于新型技术展开数字化信息资源的组织,不会造成用户焦虑水平的显著变化。当然,有一些问题也需要引起信息资源管理者的注意。
如以新技术为特征的知识组织方式初次被用户所使用时,数字资料的引入次序和不同性质的信息分析任务会造成用户一定程度的焦虑。也就是说,在将新技术应用于古籍文献的知识组织时,应注意与用户原有的阅读习惯之间做好衔接与过渡,尽量避免使用户“突然”进入新技术情境,以提高用户对于数字化古籍资源使用的舒适度[14]。
除本团队所展开的上述研究外,针对古籍文献的知识组织,图档博领域的研究者也从语义描述[3]、实体消歧[15]、古籍知识关联[16]等方面展开了大量研究。
总之,前序研究已对数字化文献的分析中应用新的技术工具与方法手段所具有的效果进行了系统检验。前序研究所获得的结果,为本文展开古籍文献知识组织基础指标的探析提供了坚实的基础。
2.1 语料选择
由西汉史学家司马迁撰写的纪传体史书《史记》是我国最伟大的典籍之一。
《史记》记述了上至上古传说中的黄帝时代,下至汉武帝太初四年间共3000多年的历史。该书包括十二本纪(记历代帝王政绩)、三十世家(记诸侯国和汉代诸侯、勋贵兴亡)、七十列传(记重要人物的言行事迹,主要叙人臣,其中最后一篇为自序)、十表(大事年表)、八书(记各种典章制度记礼、乐、音律、历法、天文、封禅、水利、财用),共130 篇,52 万余字[17]。
《史记》被列为“二十四史”之首,其首创的纪传体编史方法为后来历代“正史”所传承。《史记》还被认为是一部优秀的文学著作,在中国文学史上具有重要地位。
《史记》作为一部经典的古籍文献,在史学和文学界都享有突出地位和卓越影响。
为此,本文以《史记》作为分析语料,就古籍文献知识组织的若干实践操作问题展开实证研究,以便为解析古籍文献知识组织由静态检索向动态表征的发展路向提供实证支持。
2.2 分析程序
在前序研究已经对古籍文献知识组织由文献单元向知识单元、由静态检索向动态表征的路向进行了理论解析。
在前序研究已理出的理论脉络的基础上,本文旨在通过实证研究,对上述理论脉络加以实证分析。
具体分析程序是:
首先,应用中文古籍领域的分词工具jiayan(甲言),使用隐马尔可夫模型(Hidden Markov Model,HMM),对《史记》全文中的130 个篇章进行分词;
其次,去除分词结果中的停用词;
第三,保留分词结果中的名词;
第四,对保留下来的词语按照字数多少进行词频统计;
第五,对词频最高的部分词语在整体文本和局部文本中的分布状况进行可视化分析;
第六,对词频最高的部分词语与其周边关联词语的搭配情况进行匹配分析。
3.1 古籍文献知识组织的三个基础元素
对古籍文献进行知识组织的基本目标,是帮助减轻阅读者的认知负担,使阅读变得高效、直观、愉悦。
如前所述,基于团队前序研究成果,研究划定词频、词频的分布和词语的搭配为数字化信息资源知识的三个基础元素。
词频指古籍文献中的词语出现的频数。
词语是古籍文献知识组织的基本要素。
本文使用了研究者专门为古籍文献分词而发展的软件工具jiayan,对《史记》全文进行了分词,并保存了词性为名词的全部词语,以备进行进一步分析。
前序研究中已证明了词语分布的可视化(即本文中的“条形码”)能够辅助用户提高数字信息分析效率。为此,研究在对《史记》进行分词并保留名词的前提下,对词的分布以气泡图的形式进行了可视化呈现。
也就是说,本研究中,词语分布的可视化结果被作为古籍文献知识组织的第二个基础元素。
研究发现脱离实际语境常常是基于计算语言学原理的古籍知识计算与数字人文研究备受质疑的一个重要方面[18]。
为此,本文为防止上述两个古籍文献知识组织的基础元素脱离语境,进而以词语的搭配为古籍文献知识组织的第三个基础元素。
也就是说,在获得分词结果并制作了名词可视化工具的前提下,进而针对《史记》中每个词左右两侧所出现的词语搭配展开了分析,以便为前述两个知识组织元素提供语境信息。
总之,本文基于团队研究成果,以词频、词语分布和词语搭配为古籍文献知识组织的三个基础性元素。由此得出,古籍文献的知识组织应以上述三个要素为基准,通过应用科学的数据分析技术和知识序化方法展开研究。
3.2 文献全局特征分析
如前所述,研究以《史记》为语料对象,通过词频、词语分布的可视化和词语搭配,为古籍文献知识组织提供基础。
以下分别展示了这三个知识组织元素的初步分析结果。
(1)词频。本文应用jiayan 库,首先对《史记》全文进行了分词。在去除停用词及非名词词语后,最终在单字、两字、三字和四字上得到高频词表(见表3)。

表3 《史词》全文中的高频单字
由表3 可见,《史记》中“王”一词出现频数高达2740 次,其他出现频次较高的还包括“君”“臣”等特定称谓。
另外,国家名称(如“赵”“周”“魏”)出现频次也较高。
单字虽然从一定程度上能够反映古籍文献的内容结果,但语义单位常常不够完善。
为此,本文进一步提取二字高频词展开分析(见表4)。
由表4 可见,除“诸侯”“大夫”“陛下”等特定称谓出现频次高之外,“孔子”“高祖”“赵王”“项羽”等特定人物出现频次也很高。这些知识组织的线索,无疑能够为读者展开高效率阅读提供参考。依据同样的逻辑,进而提取三字和四字的高频词(见表5、表6)。
相比较而言,这些词语语义单位更加完整,提供的语境信息更加充分,为读者提供的语义线索也更加完善。

表4 《史记》全文中的二字高频词

表5 《史记》全文中的三字和四字高频词
(2)词的分布。前文已经完整地介绍了本团队针对数字信息分析的辅助工具,就知识组织基础元素展开的相关研究。基于前序研究的基础,本文在《史记》全文词频统计的基础上,对各种类型词语在《史记》全文中的分布状况进行了可视化分析。
以“赵”这个单字词为例,分析其在《史记》全文中的分布状况(见图2)。由图可知,在第40 号文献的位置,“赵”字出现次数高达174 次,因此其节点最大。
由于《史记》中,“赵”主要是指代“赵国”,因此,观察图2 可以快速发现,赵国在文献不同位置出现次数差异很大。此线索显然对于读者理解《史记》全貌,有针对性地发现有价值的文献线索意义重大。

图2 “赵”在《史记》全文中的分布状况
考虑到单字在表征语义方面可能存在不完整的情况,研究进而对二字词、三字词和四字词在《史记》全文中的分布进行了可视化分析(见图3)。
该分析选择以“匈奴”为二字词的代表,以“平原君”为三字词的代表,以“伯夷叔齐”为四字词的代表,分别展开了《史记》全文中上述三词的分布状况考察。
由图3 可见,研究所选择这些典型词语在《史记》全文中的分布具有鲜明的特色。如二字词“匈奴”在50-51 号文献中出现达99、94 次,但在其他部分出现的次数则相对较低。
由此可见,《史记》关于“匈奴”的记载多见于上述两个篇章。同理,从三字词“平原君”的分布可以看出,这一词语高频出现于37-46号文献之中。据此可以推断,平原君是一位仅出现于特定阶段的历史人物,与平原君相关的史料记载集中在《史记》中后篇章的情况相符。四字词“伯夷叔齐”一共再现10 次,但其中7 次集中在第31 号文献。为此,读者可按图索骥,快速获得关于“伯夷叔齐”在《史记》中的知识元素。

图3 《史记》中代表性的二字词、三字词、四字词分布状况
(3)词的搭配。
在词频分析基础上,上文展示了高频词的分布。为了丰富读者关于语境的信息,本文进而对高频词与左右相邻词语的搭配进行了进一步分析(见表6)。其中,“王”一词在《史记》全文中搭配比较多的有淮南王、秦昭王,“君”搭配比较多的有平原君、孟尝君等。
在实际的古籍文献知识组织中,可以用更加灵活便捷的形式,在更大范围对词语搭配展开分析, 以便为古籍文献的阅读者提供更加丰富、全面的语境信息。
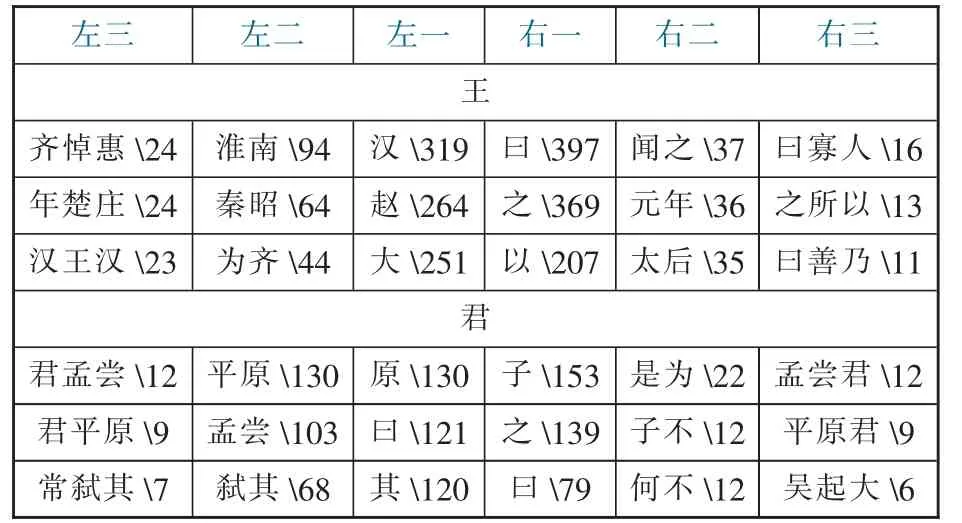
表6 高频词的搭配例析
3.3 文本的典型局部特征分析
上文针对古籍文献知识组织的三个基本元素,从《史记》全文的角度进行了解析。
在知识组织的实践中,信息资源的整理序化不仅需要从整体展开全貌的展示,更需要深入到文献的局部细节,就一些重点关注的知识元素展开表征[19]。
为此,本文在前述分析的基础上,进一步在特定局部文献的基础上展开了知识组织三元素的分析。
通过全局词频的分析和高频词分布状况的分析,发现“孔子”一词大量集中在第四十七卷。
基于此,针对《卷四十七·孔子世家第十七》,进一步进行词频统计,发现“孔子”一词在本卷出现181 次,得出其分布状况(见图4)。
由图4 可见,“孔子”一词在本卷中分布较不均衡。
这些信息,对于读者快速理解文本,把握文献主旨具有启示意义。与此相对应,对“项羽”一词进行了同样的分析,发现该词主要出现在《卷八·高祖本纪第八》中。进一步统计词频发现(见图5),“项羽”一词在某些段落比较密集,而另一些段落则非常稀疏。

图4 “孔子”一词在第四十七卷中的分布

图5 “项羽”一词在第八卷中的分布
在上述分析的基础上,对“匈奴”一词在《卷一百一十·匈奴列传第五十》中进行了高频搭配分析(见表7)。可见,“单于”“右贤王”“降”等词都与“匈奴”一词出现了较高频次的搭配,这提示阅读者,可以按此线索展开文献分析。

表7 “匈奴”一词在第一百十卷中的搭配
总之,词频统计、高频词的可视化及词语在特定篇章中的搭配,为读者减轻阅读古籍文献时的认知负担,提高数字化文献信息资源的阅读与分析效率提供了工具,这与文献资源的知识组织与序化整理的根本目标相互契合。从这个意义上说,上述三个基础元素对于实现古籍文献知识组织目标意义重大。
在本团队的前序研究中,已针对数字化资源序化整理的若干基础性要素进行了实证检验。前序研究表明,基于词频分析结果,对特定词语加以可视化,可以有效帮助用户在提高信息分析的效率的同时,降低用户在使用新技术时的不适应感。
基于前序研究,本文以《史记》为语料对象,借助于自然语言处理工具,对词频、高频词可视化呈现和词语搭配进行了分析,从而为古籍文献知识组织提供了可资借鉴的参照。
词频、高频词的可视化及词语的搭配作为知识组织的三个基础性元素,在古籍知识资源的序化整理中具有重要作用。
这启示我们,在古籍文献知识组织的过程中,要切实将知识内容的分析、表征与自然语言处理等工具、方法的使用结合起来。
通过对数字化古籍文献各种特征的深入计算、分析、建模,研究者完全可能实现古籍文献知识组织的结构与用户的认识结构的契合,从而消除文献资源“藏”与“用”之间的鸿沟[20],使古籍文献中蕴含的丰富优秀传统文化养分惠及更多的读者。
猜你喜欢高频词词频古籍30份政府工作报告中的高频词小康(2022年7期)2022-03-10省级两会上的高频词小康(2022年7期)2022-03-10基于词频分析法的社区公园归属感营建要素研究园林科技(2021年3期)2022-01-19中医古籍“疒”部俗字考辨举隅汉字汉语研究(2021年3期)2021-11-2428份政府工作报告中的高频词小康(2021年7期)2021-03-15省级两会上的高频词小康(2021年7期)2021-03-15关于版本学的问答——《古籍善本》修订重版说明天一阁文丛(2020年0期)2020-11-05关于古籍保护人才培养的若干思考天一阁文丛(2018年0期)2018-11-29我是古籍修复师金桥(2017年5期)2017-07-05词频,一部隐秘的历史读者·校园版(2015年7期)2015-05-14







