结合SS-GAN和BERT的文本分类模型
时间:2023-04-14 16:40:04 来源:柠檬阅读网 本文已影响 人 
宛艳萍,闫思聪,于海阔,许敏聪
(河北工业大学 人工智能与数据科学学院,天津 300401)
文本分类是自然语言处理领域(Natural Language Processing,NLP)中的重要分支之一,其目的是将文本按照一定的分类标准,依次归属到一个或多个类别中。目前文本分类在垃圾邮件检测、情感分析及其他领域有着广泛的应用。目前文本分类方法可分为三类:基于规则的文本分类方法、基于机器学习的文本分类方法和基于深度学习的文本分类方法[1]。
近年来,国内外关于文本分类的研究逐渐由传统机器学习向深度学习转变,许多经典深度学习模型如递归神经网络(Recurrent Neural Network,RNN)[2]、卷积神经网络(Convolutional Neural Networks,CNN)[3]和长短期记忆模型(Long Short-Term Memory,LSTM)[4]被应用到文本分类中。杨兴锐等人[5]提出了基于自注意力机制和残差网络(ResNet)的BiLSTM_CNN复合模型。通过自注意力赋予卷积运算后信息的权重,进一步提高模型的分类性能。李启行等人[6]基于注意力机制的双通道DAC-RNN文本分类模型,利用Bi-LSTM通道提取文本中的上下文关联信息,并结合CNN通道提取文本中连续词间的局部特征。
随着基于Transformer[7]的BERT模型[8]的出现,一系列大型预训练语言模型如ELMo[9]、GPT[10]、XLNET[11]和RoBERTa[12]等显著提升了自然语言处理任务的性能。越来越多的研究者开始采用预训练模型进行文本分类,但这些模型训练需要大量标注数据并且参数规模庞大,这导致了预训练时间过长且计算成本高昂,因此一直为人所诟病。
大量标注数据一般需要人工标注,获取难度高且费用贵。为解决这个问题,Weston[13]和Yang[14]等人提出可以利用半监督的方法,在标注数据量较少的情况下,同时利用未标注数据来提高模型的泛化能力。半监督生成对抗网络(Semi-Supervised Generative Adversarial Networks,SS-GANs)[15]利用了半监督的方法对生成对抗网络(Generative Adversarial Network,GAN)[16]进行扩展,在判别器中为每一个样本增加一个新类别并且判断该样本是否为自动生成的数据。在自然语言处理领域中,Croce等人[17]首次将SS-GANs应用于NLP任务中,使用SS-GANs的方法扩展基于内核的深度体系结构[18]。Croce等人[19]也从SS-GANs的角度对BERT模型进行了简单微调,将BERT模型提取特征向量,并利用半监督的方法来降低模型训练所需要的标注数据量。针对BERT模型参数过大这一问题,目前已经提出许多神经网络压缩技术,一般可以分为权重量化[20]、权重剪枝[21]和知识蒸馏[22]。Jiao等人[23]提出了更加复杂的特性模型蒸馏损失函数来提高性能。
针对目前BERT模型的缺点,利用半监督的方法在生成对抗性环境下,利用少量标注数据和大量无标注数据对BERT模型进行训练,提出了一种基于SS-GAN的BERT改进模型GT-BERT。该模型利用知识蒸馏的思路将BERT模型进行压缩,将文本输入至SS-GAN框架下的压缩模型进行训练。从而降低模型对标注数据的依赖以及模型参数规模与时间复杂度。
该文的主要贡献有:第一,提出了一种改进的BERT模型,在SS-GAN的框架下丰富了BERT的微调过程,改进了模型的整体架构,使模型能够有效利用大量无标注数据;
第二,改进了SS-GAN中生成器与判别器的选择方式,选择不同的生成器与判别器的最优配置来提高整个训练过程的效果,从而提升模型的整体性能;
第三,使用模型压缩方法Bert-of-theseus对模型进行压缩,有效降低了模型的参数规模与时间复杂度。
1.1 GAN网络
GAN网络通过生成器与判别模型器两个模块间的相互博弈,产生良好的输出。模型架构如图1所示。
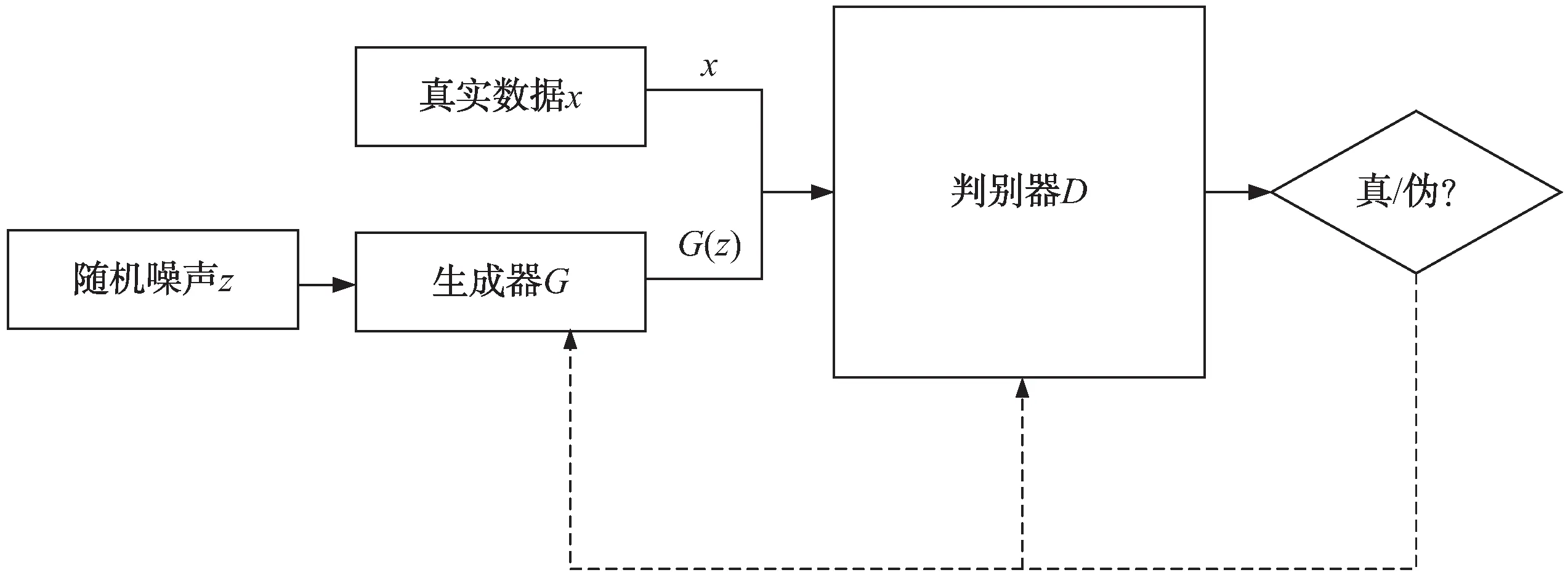
图1 GAN网络模型框架结构
图1中判别器D是一个传统的神经网络分类器,其输入的数据一部分来自真实样本数据集,另一部分来自生成器G生成的假样本数据。判别器的训练目标为对于真实样本,判别器输出概率值接近1,而对于生成器生成的假样本,输出概率值接近于0。生成器与判别器恰恰相反,其通过训练最大程度地生成接近真实样本的假样本来欺骗判别器。在GAN网络中,同时使用两个优化器来最小化判别器与生成器的损失,从而得到良好输出。
1.2 Bert-of-theseus
Bert-of-theseus[24]是基于模块的可替换性,逐步使用小模块替代BERT中的大模块来进行模型压缩。在此方法中,被替换模块和替换模块分别被称为前驱模块(predecessor)和后继模块(successor)。
theseus压缩方法的主要流程如图2所示,以将6层的BERT模型压缩至3层模型为例:首先,为两个前驱模块指定一个后继模块,在训练阶段,逐步以一定概率将后继模块替换为所对应的前驱模块。将替换后的后继模块继续放入模型中与其他剩余的前驱模块共同训练,然后依次将前驱模块替换为后继模块,直至将所有前驱模块替换完毕。当整个训练收敛后,将所有后继模块串联起来作为新模型。假设前驱模型P和后继模型S都含有n个模块,即P={prd1,prd2,…,prdn},S={scc1,scc2,…,sccn},其中,scci用来替换prdi。假设第i个模块输入为yi,前驱模型的前向过程为:
yi+1=prdi(yi)
(1)
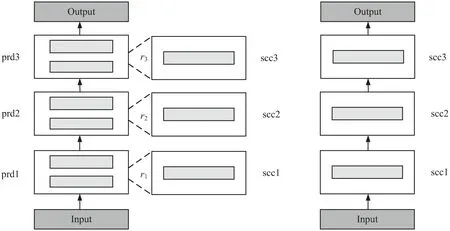
图2 Bert-of-theseus压缩流程
压缩时,对于第i+1个模块,ri+1是一个独立服从伯努利分布的变量,即以概率p取值为1,以概率1-p取值为0:
ri+1~Bernoulli(p)
(2)
则第ri+1个模块输出为:
yi+1=ri+1⊙scci(yi)+(1-ri+1)⊙prdi(yi)
(3)
其中,⊙表示逐元素相乘,ri+1∈{0,1}。通过这种方式,前驱模块和后继模块同时训练,训练的损失函数即特定任务所设定的损失函数。
在反向传播时,所有前驱模块的权重参数会被冻结,只有后继模块参数会被更新。前驱模块参数权重冻结后,其嵌入层和输出层在训练阶段会被直接当作后继模块。
当训练收敛时,所有后继模块被串起来组成后继模型S:
S={scc1,scc2,…,sccn}
(4)
yi+1=scci(yi)
(5)
由于scci比prdi规模小,因此整个前驱模型被压缩为更小的后继模型,之后后继模型将会再次使用损失函数进行微调优化,最后使用微调后的后继模型进行后续的文本分类任务。
2.1 SS-GAN
SS-GAN是对GAN网络的一种改进与扩展,利用GAN网络进行半监督学习,从而使大量无标注数据能够作为训练数据参与模型训练,降低模型对标注数据的依赖。判别器D对输入的每一个样本进行分类,同时区分该样本是否为生成器G生成的假样本。SS-GAN将GAN的判别器D改为k+1类,其中第k+1类为异常类:当判别器D将输入数据鉴别为真实样本时,将数据分至(1,2,…,k)中其中一类;
当将输入数据鉴别为生成器G生成的假样本时,将数据分至第k+1类中。为了训练半监督的k类分类器,将生成器D的目标扩展如下:

LD=LDsup+LDunsup
(6)
其中:
(7)
(8)
其中,pr和pg分别表示真实数据和生成数据。LDsup表示判别器D的有监督损失,即在判别过程中判别器D将真实样本在(1,2,…,k)类中分类错误的损失。LDunsup表示D的无监督损失,即判别器D将无标注的真实样本分至k+1类中,或将生成器生成的假样本错误判断为真实样本的损失。利用判别器中间层的输出,使得生成数据与真实数据的特征相匹配,直观上来讲判别器的中间层为特征提取器,用来区别真实数据与生成数据的特征。因此G应该尽可能生成近似真实的数据样本,f(α)表示D中间层的输出,G的特征匹配损失函数定义为:
(9)
此外,G的损失也应考虑生成器D正确判别出G所生成的假样本所产生的损失,因此:
(10)
因此,G的损失函数为:
LG=LGfeaturemmathing+LGunsup
(11)
2.2 GT-BERT
为了使BERT模型能够得到广泛的应用,在保证模型分类准确率不降低的情况下,减少模型参数规模并降低时间复杂度,提出一种基于半监督生成对抗网络与BERT的文本分类模型GT-BERT。模型的整体框架如图3所示。

图3 GT-BERT模型架构
首先,对BERT进行压缩,通过实验验证选择使用Bert-of-theseus[24]方法进行压缩得到BERT-theseus模型。损失函数设定为文本分类常用的交叉熵损失:
L=-sumj∈|x|∑c∈C[1[zj=c]·logp(zj=c|xj)]
(12)
其中,xj为训练集的第j个样本,zj是xj的标签,C和c表示标签集合和一个类标签。
接着,在压缩之后,从SS-GANs角度扩展BERT-theseus模型进行微调。在预训练过的BERT-theseus模型中添加两个组件:(1)添加特定任务层;
(2)添加SS-GANs层来实现半监督学习。本研究假定K类句子分类任务,给定输入句子s=(t1,t2,…,tn),其中开头的t1为分类特殊标记“[CLS]”,结尾的tn为句子分隔特殊标记“[SEP]”,其余部分对输入句子进行切分后标记序列输入BERT模型后得到编码向量序列为HBERT=(hCLS,ht1,…,htn,hSEP)。
将生成器G生成的假样本向量与真实无标注数据输入BERT-theseus中所提取的特征向量,分别输入至判别器D中,利用对抗训练来不断强化判别器D。与此同时,利用少量标注数据对判别器D进行分类训练,从而进一步提高模型整体质量。
其中,生成器G输出服从正态分布的“噪声”hfake,采用CNN网络,将输出空间映射到样本空间,记作hfake∈Rd。判别器D也为CNN网络,它在输入中接收向量h*∈Rd,其中h*可以为真实标注或者未标注样本hreal,也可以为生成器生成的假样本数据hfake。在前向传播阶段,当样本为真实样本时,即h*=hreal,判别器D会将样本分类在K类之中。当样本为假样本时,即h*=hfake,判别器D会把样本相对应的分类于K+1类别中。在此阶段生成器G和判别器D的损失分别被记作LG和LD,训练过程中G和D通过相互博弈而优化损失。
在反向传播中,未标注样本只增加LDunsup。标注的真实样本只会影响LDsup,在最后LG和LD都会受到G的影响,即当D找不出生成样本时,将会受到惩罚,反之亦然。在更新D时,改变BERT-theseus的权重来进行微调。训练完成后,生成器G会被舍弃,同时保留完整的BERT-theseus模型与判别器D进行分类任务的预测。
3.1 数据集设置
本节验证了GT-BERT在不同数据集下文本分类的性能。分别在20 News Group(20N)、Stanford Sentiment Treebank(SST-5)、Movie Review sentiment classification data(MR)和TREC四个数据集上进行实验。具体数据集设置如表1所示。
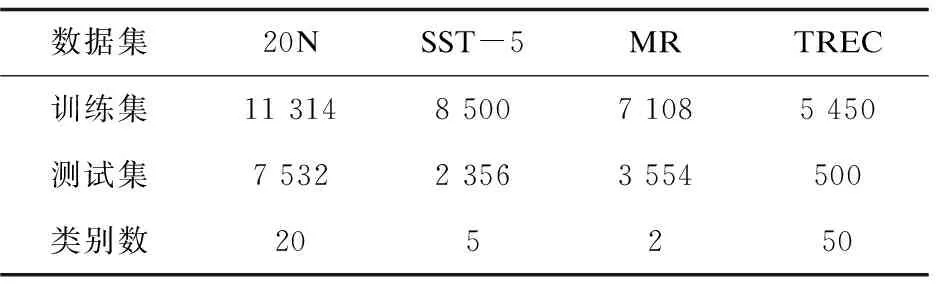
表1 数据集设置
为了更好地研究模型在小样本数据下的分类性能,并且避免抽取小样本而带来原有数据集类别分布失衡的情况发生,该文在保证实验数据集与原有数据集中各个数据类别比例相同的情况下,分别抽取数据集中2%、10%和50%的三组数据进行训练,来对比不同数据量下各个模型的训练效果。此外,还为GT-BERT模型额外提供一组无标签数据(|U|=100|L|,其中|U|表示无标签数据量,|L|为有标签数据量)参与训练。针对特定的数据集,设定了该数据集常用的评价指标,即SST-5、TREC和MR数据集的评价指标为准确率(accuracy),20N数据集的评价指标为F1值。
3.2 Baseline设置
将GT-BERT模型与目前较为先进的文本分类模型进行了对比实验,对比模型分别为BERT、GAN-BERT、CNN、LSTM、RoBERTa、XLNet、ALBERT[25]、BERT-theseus[24]、GAN-Bt、GAN-DB、GAN-MB、GAN-TB。其中GAN-Bt、GAN-DB、GAN-MB和GAN-TB分别为将BERT-theseus、DistillBERT[26]、MobileBERT[27]和TinyBERT[23]压缩模型放入半监督GAN网络的环境下进行微调所得到的新模型。
3.3 实验过程
使用BERT-base作为训练起点。首先进行压缩,在模型压缩中,采用渐进式替换策略来改进Bert-of-theseus方法中固定概率p的替换方法,后继模块替换前驱模块概率pd会随着时间增加:
pd=min(1,φ(t))=min(1,kt+b)
(13)
其中,t为训练步长,k>0为系数,b为基本替换概率。在压缩的初始阶段,当φ(t)<1时,替换模块的数量是pd,n个后继模块的平均学习率为:
(14)

在扩展阶段,G和D都为CNN,激活函数为leaky-relu函数。G的输出为噪声,是由从服从N(0,1)中提取的噪声向量通过CNN后变成的768维向量组成的。D也为一个CNN,隐藏层激活函数与D相同,在最后一层利用softmax进行分类。在训练过程中epoch设置为4,学习率为2×10-5(20N数据集的学习率为5e-6),batch size为32,dropout设定为0.1,其他超参数和Devlin等人[8]设定的超参数一致。
除去有特殊说明的情况外,最终每一个模型都在各个测试集上执行5次独立测试,并计算5次测试得到的平均值。
3.4 结果与分析
3.4.1 模型文本分类性能比较
表2展示了各个模型在四种数据集上针对文本分类任务的性能对比。如表2所示:GT-BERT模型在20N数据集所有数据设置下以及其他数据集绝大部分情况下相比于其他模型都取得了最佳性能。

表2 模型分类性能对比
由表2可知,在使用较少的标注数据时,BERT模型与其他单独的预训练模型的效果都不尽如人意,而GAN-BERT等其他将预训练模型放入半监督环境下微调所得到的模型此时分类效果整体较为良好,尤其在使用50%的TREC数据集进行训练,GAN-BERT模型取得了最优效果。这证明将预训练语言模型放入半监督生成对抗框架下利用额外的无标注数据进行微调,能够有效提升模型在低标注数据量下的模型分类性能。
该文着重对比了GT-BERT与BERT、GAN-BERT模型,在20N数据集、SST-5数据集和TREC数据集下,当使用2%的数据进行训练时,BERT模型的F1值和准确率分别仅为32.5%、25.1%和10.2%。而GT-BERT和GAN-BERT模型相对应值分别为54.2%、36.2%、45.9%和51.0%、35.2%、45.6%,远高于BERT模型。因此,当标注数据使用量低时,BERT模型的分类效果较差,与其他两个模型的差距较大。随着训练使用的标注数据量的增加,三者分类性能随之提升同时之间的差距逐渐缩小,但绝大多数情况下GT-BERT仍取得了最佳效果。尤其在20N与TREC数据集下,当只采用数据集中2%的数据(约220条和109条数据)训练时,GT-BERT模型性能指标分别为54.2%和45.9%。相较于BERT模型提升了21.7百分点和35.7百分点。这可能表明,当涉及到大量类别时,即当分类任务越复杂时,半监督学习方法的提升效果越好。
3.4.2 压缩方法对比实验
BERT-theseus与BERT在各个数据集下表现大致相似,但参数量却降低一倍[24]。由表2可得:与其他将其他压缩模型放入SS-GANs框架下微调后模型相比,GAN-Bt在各个数据集下都获得了良好结果。与原始未经压缩的GAN-BERT相比,GAN-Bt在20N数据集下使用10%的数据时,F1值为68.6%,在MR数据集下使用2%的数据时,准确率为65.6%,都略高于GAN-BERT模型,其他情况下两者相似。因此,选用theseus方法对BERT进行压缩并放入SS-GANs的环境下进行微调。
3.4.3 生成器与判别器最佳配置选择实验
为了探究不同生成器和判别器对模型的影响并获取最优配置,针对不同的生成器判别器配置组合在四种数据集下进行实验,结果如表3所示。为了不增加模型整体参数规模与运行时间,生成器与判别器选择MLP、CNN和LSTM这三种传统神经网络。表中GAN-Bt-MC表示GAN-Bt模型的生成器为MLP、判别器CNN,GAN-Bt-MM表示GAN-Bt模型的生成器、判别器均为MLP,其他模型的表示方式与此同理(GT-BERT模型中生成器和判别器皆为CNN。GAN-Bt模型生成器与判别器为MLP,为了实验对比方便明显,在此表示为GAN-Bt-MM)。

表3 不同生成器与判别器对模型的影响
由表3可知,生成器与判别器都为CNN时,模型在绝大多数数据集设置下取得了最优性能。此外,当判别器为CNN时,各个模型取得了相对良好的结果。如GAN-Bt-MC在MR数据集下使用50%的数据时,准确率达到85.8%;
GAN-Bt-LC在SST-5数据集与TREC数据集下,分别使用2%和10%的数据时,各自性能指标分别达到36.4%和73.2%。当生成器为LSTM时,各个模型取得了不错的训练结果,如GAN-Bt-LM在使用10%的20N数据集的情况下,F1值为70.8%;
GAN-Bt-LL在TREC数据集使用率为2%时,准确率为46.2%。虽然当仅考虑单独的生成器或判别器时,或许GAN-Bt-LC配置为最优选择,但整体而言GT-BERT性能仍远高于GAN-Bt-LC。原因可能为与CNN相比,LSTM参数较多、训练难度较大。实验中为了公平起见,该文对于生成器与判别器的更新频率参数设置相同,这有可能导致GT-BERT模型最终结果最优。因此,选择生成器与判别器都为CNN作为最终模型的配置。
3.4.4 模型参数规模与时间复杂度
为了比较模型的参数规模,就目前几种模型的层数与参数进行了对比,见表4。
由表4可以看到,新模型的参数规模相较于原始BERT模型以及未进行压缩的GAN-BERT模型有很大降低。BERT模型与GAN-BERT模型为120 M参数,而GT-BERT模型参数仅有66 M大小。虽然ALBERT、TinyBERT和MobileBERT模型的参数规模较小,但各个数据集中分类性能较差,在标记数据量小时,不能很好地应用于实际生产中。

表4 模型参数规模对比
图4为在四个数据集下、使用10%的数据时,各个模型之间文本预测时长的对比图。由图4可知,GT-BERT的预测耗时在不同数据集下都明显小于其他模型。在SST-5数据集下,预测时间仅为48 s,其他模型中耗时最低的BERT为60 s,耗时最高的XLNet为80 s。
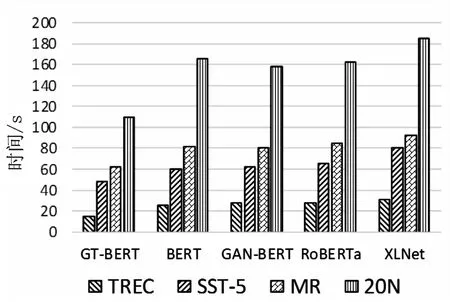
图4 模型预测时间对比
由上述结果可以看出,在标注数据量较低的小样本数据集中,所提模型可以有效地利用无标注数据,提升模型的分类性能,同时降低模型的参数规模和时间复杂度。
该文提出了一种用于文本分类任务的GT-BERT模型。首先,使用theseus方法对BERT进行压缩,在不降低分类性能的前提下,有效降低了BERT的参数规模和时间复杂度。然后,引入SS-GAN框架改进模型的训练方式,使BERT-theseus模型能有效利用无标注数据,并实验了多组生成器与判别器的组合方式,获取了最优的生成器判别器组合配置,进一步提升了模型的分类性能。实验结果表明,提出的GT-BERT模型能够有效利用无标注数据,降低了模型对标注数据的依赖程度,在标注数据量较小的数据集上的文本分类性能显著高于其他模型,并且拥有较低的参数规模与时间复杂度。
猜你喜欢后继前驱分类分类算一算数学小灵通(1-2年级)(2021年4期)2021-06-09分类讨论求坐标中学生数理化·七年级数学人教版(2019年4期)2019-05-20数据分析中的分类讨论中学生数理化·七年级数学人教版(2018年6期)2018-06-26教你一招:数的分类初中生世界·七年级(2017年9期)2017-10-13皮亚诺公理体系下的自然数运算(一)湖南教育(2017年3期)2017-02-14SiBNC陶瓷纤维前驱体的结构及流变性能材料科学与工程学报(2016年1期)2017-01-15甘岑后继式演算系统与其自然演绎系统的比较贵州工程应用技术学院学报(2016年3期)2016-08-19滤子与滤子图东北师大学报(自然科学版)(2016年2期)2016-06-30可溶性前驱体法制备ZrC粉末的研究进展当代化工研究(2016年7期)2016-03-20前驱体磷酸铁中磷含量测定的不确定度评定电源技术(2015年9期)2015-06-05







