基于锚点图的低秩缺失多视图子空间聚类
时间:2023-03-11 15:10:04 来源:柠檬阅读网 本文已影响 人 
刘小兰 石宗宇 叶泽慧 梁勇
(华南理工大学 数学学院,广东 广州 510640)
多视图数据是对同一个物体不同方面的特征的描述,如一份新闻文稿,它有多个不同的版本,这些不同版本的报道形成一个多视图数据集。多视图聚类算法则聚焦于如何利用物体的多视图信息来获得更好的聚类结果[1-3]。在实际任务中,受限于各种因素,完整的数据一般难以获取,对缺失多视图数据进行聚类产生了缺失多视图聚类问题。
目前常见的缺失多视图聚类算法分为3类:基于非负矩阵分解的方法[4-7]、基于深度学习的方法[8]、基于谱聚类的方法。基于非负矩阵分解的方法通常利用非负矩阵分解(NMF)来获得共同表示。Li等[4]利用NMF和L1正则化来学习数据共同的潜在空间,提出了部分多视图聚类(PVC)算法,但它只能解决两个视图的情形。Shao等[5]通过加权的方式将完整多视图中的NMF拓展到缺失多视图,提出了多视图不完全聚类(MIC)算法。Hu 等[7]通过半NMF和L2,1正则化将PVC 算法拓展为双对齐缺失多视图聚类(DAIMC)算法。Hu 等[9]针对常见NMF 方法中无法处理大规模数据的问题,提出了一步缺失多视图聚类(OPIMC)算法。以上基于NMF的算法都取得了很好的效果,但它们在处理负值数据和刻画数据的潜在结构方面仍有不足。基于谱聚类的方法根据聚类图的构造方法不同又分为两种:①通过学习数据点的相似图进行聚类,其中最具代表性的是基于子空间聚类的方法。Wen 等[10]利用扩维的方法对齐缺失多视图数据,以解决不同视图相似矩阵维度不一致的问题,再根据一致性原则对对齐后的相似矩阵进行谱聚类。文献[11]采用了与文献[10]相同的对齐相似矩阵的策略,同时引入流形正则化,提出了一致性指导下的缺失多视图谱聚类(CGIMVSC)算法。文献[12]针对现有方法大多聚焦于成对视图之间的相似性而忽略了样本中的高阶关联性,通过引入三阶张量来挖掘缺失多视图中的子空间结构,提出了高阶(HCP-IMSC)算法。②通过直接计算数据点之间的度量来得到相似矩阵并进行聚类,其中最具代表性的是通过构造锚点图的快速算法[13]。Kang等[14]将构造锚点图与二向图优化相结合,挖掘锚点与数据点的潜在结构,提出了基于多视图结构图学习(MSGL)。Guo等[15]将完整多视图中基于锚点图构造的快速算法推广到缺失多视图,提出了基于锚点图的缺失多视图聚类(APMC)算法。APMC 算法利用成对视图中共有的数据来选取锚点集,取得了不错的聚类效果。由于缺少了对数据整体结构的刻画,故APMC算法的性能较其他算法仍有差距。
为了充分利用APMC算法的高效性,同时提升其性能,本文提出了一种基于锚点图的低秩缺失多视图子空间聚类(ALIMSC)算法。首先利用APMC 算法的锚点图得到数据的基准相似矩阵,为了进一步提升其性能,同时考虑每个视图的低秩自表示矩阵,本文通过升维对齐维度后进行加权融合,得到相似矩阵,从而使两个相似矩阵趋于共同的相似矩阵;
然后以最终优化得到的相似矩阵为聚类图进行谱聚类;
最后在几个公开的数据集上进行实验,以验证本文算法的有效性。
1.1 问题描述
设X={X(1),X(2),…,X(v),…,X(V)}(v=1,2,…,V)为待聚类的缺失多视图数据集,它包含了V个视图,第v个视图的数据矩阵为X(v)= [,,…,]∈Rdv×nv,nv为视图Xv中样本的个数,dv为样本的维度;
Cv∈Rnv×nv,为第v个视图的自表示相似矩阵,代表了视图的子空间结构;
ψ是元素全为1 的列向量。设实例总数为n,对于缺失多视图子空间聚类,每个视图中样本个数小于等于总的实例个数,即nv≤n(v=1,2,…,V)。该问题的最终任务是在获得每个子空间的结构的同时获得数据的聚类结果。
1.2 缺失多视图子空间聚类
完整数据的多视图子空间聚类算法可用如下框架进行描述[3]:

式中,α为平衡系数,R(C1,C2,…,CV)为对每个视图的自表示矩阵进行约束的正则项。通过正则项来学习一致性矩阵,并将它应用于谱聚类得到最终的聚类结果。
对于缺失多视图子空间聚类问题,第v个视图上学习到的相似矩阵的维数是nv×nv,不同视图的nv可能不相等,因此无法直接通过加权融合的方法将其集成。IMSC_AGL[10]使用指示矩阵P(v)∈{0,1}nv×n记录每个实例在对应视图出现与否,当实例在该视图中有样本时取值为1,否则为0。第v个视图的拉普拉斯矩阵为Lv=Dv-Cv,其中Dv为对角阵,对角线上的元素为Cv的每行元素之和。通过变换P(v)TLvP(v)将Lv扩维为n×n矩阵,达到维数对齐的目的。对相似矩阵Cv添加低秩性和一致性正则化,得到IMSC_AGL的模型为

式中:Fv∈Rn×c为正交矩阵,每行包含了数据的聚 类 信 息;
c为 聚 类 数;
Ev∈Rdv×nv,为 噪 声 项;
U∈Rn×n包含了所有视图的共有信息,表现为视图的一致性。
1.3 APMC算法
APMC 算法[15]将视图两两分为一组,每组选取两个视图上都存在的数据作为锚点集,如图1所示(图中展示的是k=2 的情形,视图1 中缺失了实例5和实例6,视图2中缺失了实例1)。对每一个实例,计算与其距离最近的k个锚点的高斯距离,以此得到n个实例与锚点之间的锚点图Z(v)为

图1 APMC中锚点图的构造方法(k=2)Fig.1 Construction method of anchor graph in APMC (k=2)

式中:Z(v)∈Rnv×m,表示第v个视图中实例和锚点之间的相似性;
D( )·,· 是某种距离度量;
σ是参数,通常设置为1;
iv表示那些距离最近的k个锚点的指标。
在得到所有的Z(v)之后,APMC 算法通过图重构 的 方 法 将Z(v)重 构 为nv×nv的 相 似 矩 阵Cv,即第v个视图中样本点之间的相似图。然后根据每一个实例在不同视图中的缺失与否,将得到的v个相似图加权融合,得到最终的n×n的相似图,即所有实例之间的相似图,并将它应用于最终的谱聚类。
APMC 算法有不错的聚类性能,但它缺乏对数据整体结构的刻画。为了充分发挥APMC算法的优势,同时考虑低秩性对数据整体结构的刻画,本文提出了一种基于锚点图的低秩缺失多视图子空间聚类算法ALIMSC。首先利用APMC 算法生成基准相似矩阵,以得到一个较好的初始解;
然后加入子空间聚类框架中,将基准相似矩阵与每个视图的低秩自表示矩阵对齐升维后加权融合,得到新的相似矩阵并进行集成,利用集成后的聚类图进行谱聚类得到最终聚类结果。
2.1 算法描述
设S∈Rn×n为APMC 算法生成的锚点图(相似矩阵),APMC 算法是通过直接计算样本点和锚点的相似矩阵来获得聚类图的,但由于对数据的全局结构欠考虑,故性能有待提升。假设第v个视图的低秩自表示矩阵为Cv∈Rnv×nv,以往的子空间聚类方法主要采用同时优化一致性项和自表示矩阵来实现一致性原则,即同时优化式(2)中的U和Cv。同时优化这两个对象容易使得一致性项落入性能较差的局部最优解中,因此使用一个有足够高性能的预设图来作为一致性项,只单独优化Cv是一个比较好的选择,即

式 中,w=[w1,w2,…,wi,…,wV],wv∈[0,1]为对应视图的权值。使用固定的一致性项S作为基准而只优化Cv的策略能够让wvP(v)TCvP(v)落在S的附近,这样wvP(v)TCvP(v)的性能也能够得到保障,因此能够避免同时优化时容易落入局部最优的问题。
但在得到了一致性项之后,还不能直接将它应用于谱聚类之中。注意到wvP(v)TCvP(v)是维度对齐后相似矩阵的加权融合,而这样得到的矩阵在结构上具有一些不好的性质,如图2所示,视图1中缺失了实例7、8、9、10,视图2中缺失了实例3、4、5、6,图中的空白格表示缺失实例在对齐时所对应的那些全零向量。从图2可知,在融合后的相似矩阵中,缺失的实例之间所对应的系数都为0。当缺失率不断增大时,融合后的相似矩阵对缺失样本的刻画越来越少,大多数保留下来的都是单个视图的结构信息。使用这样的图进行聚类会极大地降低聚类结果的正确率。
为了解决上述问题,本文引入变量Z∈Rn×n作为最终的相似图,它同时继承S和wvP(v)TCvP(v)中的聚类信息,即

接下来将模型(5)与IMSC_AGL 中所使用的低秩表示模型[16]进行结合。具体的方法是使用矩阵的核范数以及自表示重构误差来对每个Cv进行约束,然后加入模型(5)中一起优化,最终得到所提出的ALIMSC算法的模型:
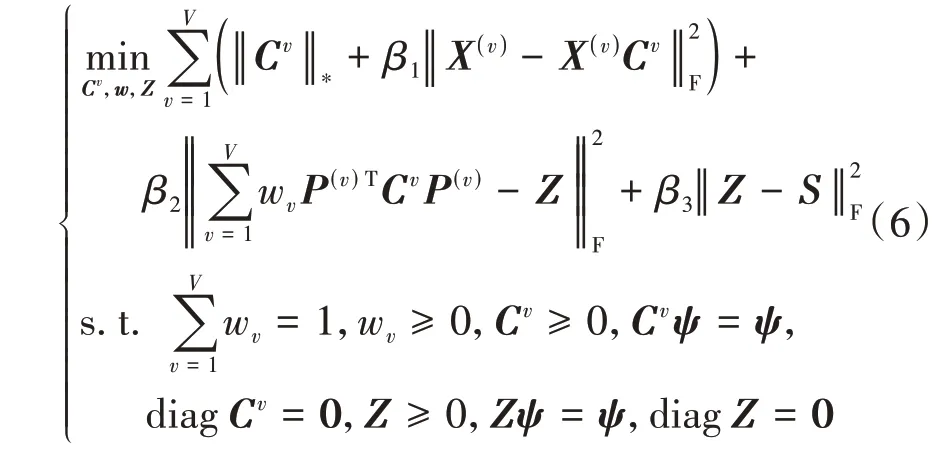
式中,β1、β2、β3为平衡系数,对Cv和Z施加的标准化约束能提升相似图的质量并且避免平凡解的产生。在求得最优解Z之后对它进行谱聚类,可得到最终的聚类结果。
与现有的缺失多视图子空间聚类算法相比,ALIMSC算法具有以下特点:
(1)ALIMSC算法利用预先构造的锚点图来达成一致性,而非使用共同优化的策略,这样能有效地限制最终结果的范围,使得模型的性能有较好的保障;
(2)ALIMSC 算法通过对模型施加适当的约束,将基于子空间表示的相似图和基于高斯距离生成的锚点图进行融合,使用锚点图来填补自表示相似图中关于缺失样本的信息,从而构造出一个更优的聚类图。
2.2 模型求解
本文运用交替方向乘子法(ADMM)[17]来求解优化问题(6)。引入辅助变量Ev、Dv和Z",将问题(6)改写为如下形式:

对应的增广拉格朗日函数为

1)固定其他变量,更新Cv,即求解优化问题

利用奇异值阈值算子(SVT)[18]可得其解

式中,Π为SVT算子,Πβ(Y)=Uπβ(Σ)VT,Y=UΣVT是Y的SVD 分解,πβ(Σ) =(Σ-β)+是软阈值算子,t+= max(0,t)。
2)固定其他变量,更新Dv,即
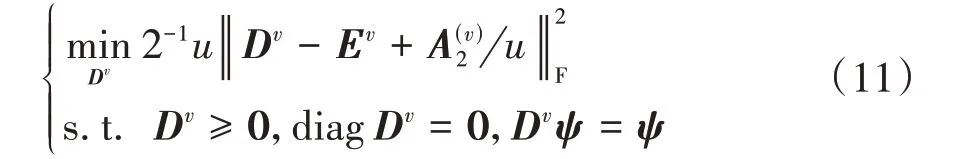
该问题可由迭代算法[19]进行求解。
3)固定其他变量,更新Ev,即
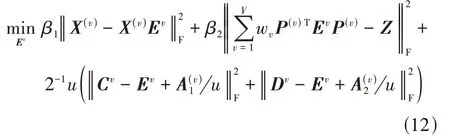
令式(12)对Ev的偏导数为0,得到

由P(v)P(v)T=I可得Ev的解析解

4)固定除wv以外的所有变量,更新w,则问题化为

记Mv=P(v)TEvP(v),则上述问题可以化为

这是一个关于w的二次规划问题[20],可以使用Matlab中的二次规划函数Quadprog进行求解。
5)固定其他变量,更新Z,即

令其对Z的偏导数为0,得到

化简可得Z的解析解
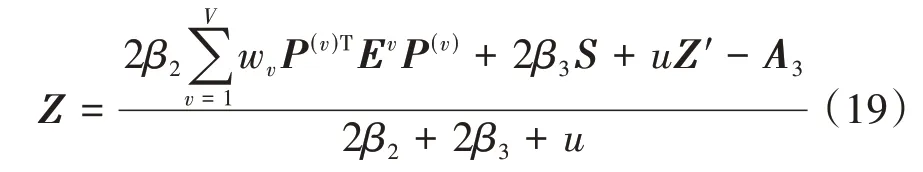
6)固定其他变量,更新Z",即

此问题和问题(11)是同样的优化问题,因此使用求解Dv子问题的方法即可得到结果。
7)更新拉格朗日乘子和罚参数

式中,ρ> 1,u0是常数。
ALIMSC算法描述如下:

在得到了聚类图Z之后,对Z进行谱聚类,可得到最终的聚类结果。
2.3 算法复杂度分析
求解ALIMSC模型的时间消耗主要来自于:①解问题(9)的SVD 分解操作,时间复杂度为O();
②解问题(12)的矩阵求逆,时间复杂度为O();
③解问题(15)的二次规划求解,时间复杂度为O(V3);
④使用迭代算法[19]求解问题(11)和(20),时间复杂度分别为O()和O(t2n2),t1、t2分别是两个问题所需要的迭代次数;
⑤对Z进行最终的谱聚类,时间复杂度为O(n3)。因此算法总的时间复杂度为为整个算法的迭代次数。
将本文ALIMSC 算法与经典的PVC[4]、MIC[5]、DAIMC[7]和 最 近 提 出 的OPIMC[9]、HCP-IMSC[12]、IMSC_AGL[10]和APMC[15]算法在多个公开数据集上进行实验比较。实验采用Matlab R2021a,在Intel Core i7-11800H 2.3 GHz CPU、16 GB RAM计算机上实现。
3.1 实验数据集
选用的6 个多视图数据集分别是3Source、USPS-MNIST、UCI Digit、BBCSports、ORL和WebKB,详细的信息如表1所示。

表1 数据集描述Table 1 Descriptions of datasets
3Source[21]数据集来源于BBC、Reuters、Guardian上的948篇新闻报道,其中包括了416个新闻内容。
遵 循 文 献[15]中 的 做 法, 将USPS[22]和MNIST[23]中的每个数字,随机选取50个样本作为对应视图中的数据,以此组成一个视图数为2、实例个数为500的二视图数据集USPS-MNIST。
UCI Digit[24]数据集共由6 个视图组成,每个视图都由200×10 个数据样本组成,遵从文献[25]中的设定,从中选取字母的傅里叶系数和轮廓相关性这两个视图作为二视图Digit数据集。
BBCSports[26]数据集收录了544 份BBC 体育的报道,每份报道分为两个部分,代表了数据集中的两个视图。所有的报道最终被归结为5个大类,代表了5个类别。
ORL数据集是常见的人脸识别数据集,它由4个视图组成,数据样本的维度分别为512、59、864、254。实验中选取数据集的前3个视图组成1个三视图数据集。
WebKB[4]数据集包含了4 个大学中共5 个类别的网页信息。这里选取其中的203条数据,它们包含了其中的4 个类别,每个类别中的数据由1 个内容视图和2 个引用视图的数据组成,最终组成1 个三视图的多视图数据集。
3Source 数据集是一个缺失多视图数据集,因此可以直接使用它进行实验。其他几个数据集都是完整的多视图数据集,因此采取随机删去其中一部分样本的方法来构造它们对应的缺失多视图数据集。具体地,对于每个数据集,给定0.1、0.3、0.5、0.7 和0.9 的缺失率(PDR,rPD),随机删除对应比例的样本来构造缺失数据集。
3.2 对比算法的参数设置与评价指标
使用网格法来寻找最优的参数。对于PVC的λ、MIC和DAIMC的α、β,从{10-5,10-4,10-3,10-2,10-1,1,10,102,103,104,105}中遍历选取。对于OPIMC的α,从{10-4,10-3,10-2,10-1,1,10,102,103}中遍历选取。对于HCP-IMSC 的α和β,从{10-3,10-2,10-1,0.5,1,2,3,5,10,50}中遍历选取。对于IMSC_AGL,λ1从{10-2,10-1,1,10,102}中遍历选取,λ2和λ3从{10-4,10-3,10-2,10-1,1,10,102,103,104}中遍历选取。在APMC算法中,对每个数据集分别选取2~30个锚点进行实验,取性能最高的结果作为APMC算法的实验结果。对于ALIMSC 算法,选取APMC 算法中最高性能的结果作为输入的锚点图S,β1、β2、β3在UCI-Digit 数据集上从{10-1,1,10,102,103}中遍历选取,而在其他数据集上则从{10-2,10-1,1,10,102,103}中遍历选取,选取最优的参数组合。采用聚类准确率(ACC)和标准化互信息量(NMI)[27]两个指标来评价聚类结果,指标值越高代表聚类效果越好。
基于非负矩阵分解的方法PVC、MIC 和DAIMC,取10 次运行的ACC 和NMI 的平均值作为最终的实验结果。对于OPIMC,参照文献[9]的设定,直接输出最终聚类结果的ACC 和NMI。对于HCP-IMSC,参照文献[12]的设定,取20 次谱聚类结果的ACC 和NMI 的平均值作为最终聚类结果。对于APMC、IMSC_AGL和ALIMSC,首先得到最终的聚类图,然后对其进行10 次谱聚类,取ACC 和NMI的平均值作为最终结果。
3.3 实验结果分析
8种算法在6个数据集上的实验结果如图3、表2和表3 所示。PVC 是针对两个视图的算法,因此在三视图数据集上没有实验结果。从图3、表2和表3可以看出,与基于锚点图的APMC算法相比,除了在BBCSports数据集上当缺失率为0.1、0.3、0.5时出现了持平的情况外,ALIMSC 算法在其他情形下的ACC和NMI平均值均比APMC算法高出2个百分点以上,最高的甚至达到了10个百分点。

表2 8种算法在USPS-MNIST、UCI Digit数据集上的聚类结果Table 2 Clustering results of eight algorithms on USPS-MNIST and UCI Digit datasets

表3 8种算法在3Source上的聚类结果Table 3 Clustering results of eight algorithms on 3Source dataset
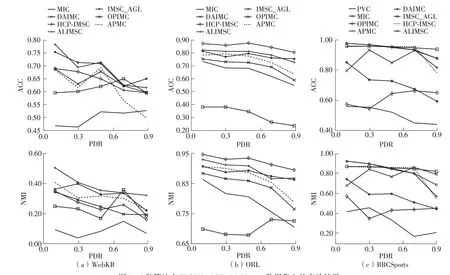
图3 8种算法在WebKB、ORL、BBCSports数据集上的实验结果Fig.3 Experimental results of 8 algorithms on WebKB, ORL and BBCSports datasets
与经典的PVC 和MIC 算法相比,ALIMSC 算法的性能提升是明显的。在3Source、WebKB 和UCI Digit数据集上,ALIMSC 的ACC 和NMI均高出PVC和MIC 算法10 个百分点以上。与DAIMC 算法相比,ALIMSC 算法在WebKB 和ORL 数据集上的ACC 和NMI普遍能高出5个百分点,最高则达到了10 个百分点;
而在剩余的4 个数据集上,ALIMSC算法与DAIMC 的差距被迅速拉大,最大的性能差距甚至达到了30 个百分点。与快速算法OPIMC 相比,ALIMSC 算法除了在0.7 缺失率下的WebKB 数据集上的ACC 和NMI 只有2~3 个百分点的差距外,在其余数据集上的性能都有大幅度的提升。
对比IMSC_AGL 算法,ALIMSC 算法在大多数据集上的性能提升显著。在3Source 和UCI Digit 数据集上,ALIMSC 算法的性能明显优于IMSC_AGL算法。在USPS-MNIST、WebKB、ORL 数据集上,当缺失率小于0.9 时,ALIMSC 算法在0.3 缺失率下的WebKB 数据集上的ACC 和在0.7 缺失率下的ORL 数据集上的NMI 仅比IMSC_AGL 低1 个百分点左右,除了这两个特殊的缺失情形外,ALIMSC 在这3 个数据集上的性能都要优于IMSC_AGL;
当缺失率达到0.9 时,ALIMSC 算法的性能不如IMSC_AGL 算法。在BBCSports 数据集上,ALIMSC和IMSC_AGL 算法的性能持平,在0.1 和0.3 缺失率的情形下ALIMSC算法的性能占优,在0.7和0.9缺失率的情况下IMSC_AGL 算法的性能占优,在0.5 缺失率的情形下两种算法的性能基本持平。ALIMSC 算法在高缺失率情况下性能欠佳的原因在于,高缺失率的数据集中所包含的大量空白样本充当了噪声项的作用,而ALIMSC算法中并没有考虑到噪声的影响,因此更具鲁棒性的IMSC_AGL算法在高缺失率的数据集上的性能要略优于ALIMSC算法。
与HCP-IMSC算法相比,ALIMSC算法在USPSMNIST、UCI-Digit和WebKB数据集上的性能是最优的;
而在BBCSports数据集上,ALIMSC算法在0.1、0.3、0.9缺失率下的性能优于HCP-IMSC 算法,在0.5、0.7 缺失率下两种算法的性能基本持平。在3Source数据集上,ALIMSC算法在3个二视图情形下的ACC 分别高出HCP-IMSC 算法5.3、1.7和5.9个百分点,NMI则分别高出8.0、1.6、10.7个百分点;
在三视图情形下两种算法的ACC 持平,而ALIMSC算法的NMI则低于HCP-IMSC算法1.4个百分点。在ORL数据集上,ALIMSC算法的性能则落后于HCPIMSC算法。经分析发现,HCP-IMSC算法引入了张量来刻画数据的结构,而ALIMSC算法是处于矩阵的层次上考虑成对视图间的关系,因此HCP-IMSC 算法在处理三视图图像数据时有明显的优势。
3.4 收敛性分析
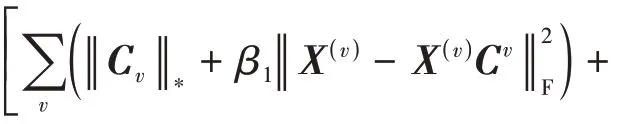

图4 ALIMSC 算法在BBCSports(rPD=0.1)、ORL(rPD=0.9)数据集上的收敛性Fig.4 Convergence of ALIMSC algorithm on BBCSports(rPD=0.1) and ORL(rPD=0.9) datasets
3.5 参数敏感性分析
选用0.9缺失率的UCI Digit数据集进行实验。β1分别固定为{0.1,1,10,100,1 000},ALIMSC算法的ACC随β2、β3的变化如图5所示。从图中可以看到,在固定β1的情况下,当β2>β3时,ALIMSC的ACC性能较差;
当β2≤β3时,ALIMSC的ACC性能比前一种情况高出很多,并且具有很好的稳定性。特别地,当β2=β3时,ALIMSC的ACC性能往往能达到同样β1下的性能最高值。因此在实际的模型中,选取一个比β2大的β3,再对β1进行遍历,则能够在保证模型对参数的变化保持稳定的同时获取一个较高的ACC性能。

图5 ALIMSC算法在UCI Digit(rPD=0.9)数据集上的参数敏感性Fig.5 Sensibility of parameters in ALIMSC algorithm on UCI Digit (rPD=0.9) dataset
3.6 对聚类图的分析
对ALIMSC 模型中最终生成的聚类图Z进行分析,主要从引入Z的影响和Z的质量两个方面展开分析。使用N-ALIMSC代表如下模型:

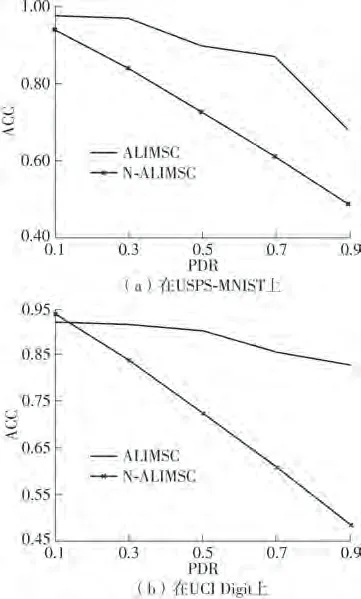
图6 ALIMSC 和N-ALIMSC 算法在UCI Digit 和USPS-MNIST数据集上的ACC对比Fig.6 Comparison of ACC between ALIMSC and N-ALIMSC algorithms on UCI-Digit and USPS-MNIST datasets

图7 3Source数据集上两种算法生成的聚类图对比Fig.7 Comparison of clustering graphs generated by two algorithms on 3Source dataset
本文提出了一种基于锚点图和低秩自表示的缺失多视图子空间聚类算法ALIMSC。首先利用APMC 算法生成的锚点图作为基准相似矩阵;
然后对每个视图的低秩自表示矩阵进行升维对齐后加权融合,得到所有数据间的自表示相似矩阵;
最后将两种相似矩阵进行结合得到最终的聚类图,并对其进行谱聚类,得到最终的聚类结果。ALIMSC 算法不仅在APMC 算法的基础上提升了其性能,还利用其高效性缓解了优化方法容易落入较差的局部最优解的问题。实验结果表明:ALIMSC 算法的聚类性能优于经典的算法和APMC算法,总体上也优于最近两年提出的IMSC_AGL算法。未来将围绕ALIMSC 算法的鲁棒性进行研究,以解决其高缺失率下聚类性能下降的问题。如何设计图之间的度量,使其能够同时利用锚点图和自表示相似图之间的结构信息,也是一个值得深入研究的问题。








