基于改进MFCC融合特征及FA-PNN的驾驶员路怒情绪识别
时间:2023-02-28 16:00:06 来源:柠檬阅读网 本文已影响 人 
李尚卿,王晓原,2,张 杨,李 浩,项 徽
1.青岛科技大学 机电工程学院,山东 青岛266000
2.青岛科技大学 智能绿色制造技术与装备协同创新中心,山东 青岛266000
在已有的交通事故致因分析中,有研究表明人为因素占到90%以上[1],在人为因素中,“路怒”正是造成交通事故的重要原因之一,其用以形容在交通阻塞情况下开车压力与挫折所导致的愤怒情绪[2],既有研究表明,我国约有60.72%的机动车驾驶员有“路怒”的经历[3]。语音是表达情绪信息的重要载体,在语音情感识别领域,高效的语音特征和适合的识别模型一直是较热门的研究方向。语音的声学特征分为两类:时域和频域特征,普遍使用的时域特征有音高、短时能量、短时过零率、平均幅度、谐波噪声比、自相关系数等;
频域特征有共振峰频率、Mel频率倒谱系数(MFCC)、线性预测倒谱系数(LPCC)、线谱对(LSP)等;
Sato等人[4]使用基于MFCC的情感识别系统证明了频域特征比时域特征对于情感识别具有更好的准确率。Bozkurt等人[5]计算了共振峰位置信息并与MFCC进行融合,在柏林数据库上得到了16.5%的识别率。Milton等人[6]将MFCC、音调、共振峰等特征组合,在柏林数据库、Savee数据库、Enterface数据库上得到了82.8%、56.3%和74.3%的准确率。Ton-That等人[7]介绍了一种语音情感分类的方法,根据MFCC特征,基于模糊推理方法进行语音情感的识别。Ancilin等人[8]利用幅值谱代替能量谱,改进MFCC特征参数进行语音情感识别,在乌尔都语数据库中识别率达到95.25%。既有的研究表明通过将梅尔频率倒谱系数进行改进或与其他特征融合,情感识别率得到了提高。基于此,本文以路怒情绪为研究对象,利用模拟驾驶系统建立数据集,分析驾驶员语音的频谱特性,将短时能量及短时过零率和改进MFCC特征融合构成特征参数向量。
获得特征参数后,利用模型对情感进行识别。目前常用的识别模型主要有支持向量机(support vector machine,SVM)、近邻算法(K-nearest neighbor,KNN)、BP神经网络(back propagation,BP)、概率神经网络(PNN)、学习向量化神经网络(learning vector quantization,LVQ)等。Shahin等人[9]证明神经网络算法比SVM识别准确率提升4.6%。Mohanty等人[10]证明PNN在情绪识别领域具有显著优势。Pawar等人[11]证明神经网络算法相对于近邻算法更好的性能评估。萤火虫算法(FA)是2009年Yang教授提出的一种启发式算法。Huang等人[12]构建了基于萤火虫算法优化径向基神经网络(radial basis function neural network,RBFNN)的嵌入式系统,结果表明系统控制性能更优。Bacanin等人[13]利用萤火虫算法寻找卷积神经网络超参数,提高轴向脑肿瘤图像分类的效率。既有的研究表明,在语音情感识别领域,神经网络算法分类性能更好,同时,萤火虫算法优化神经网络可以提高准确率和鲁棒性。基于此,本文利用萤火虫算法(firefly algorithm,FA)优化概率神经网络(PNN),建立一种驾驶员路怒情绪识别模型,在Matlab R2019a环境下利用实测数据对模型进行验证及对比分析。
1.1 采集装备、对象及数据要求
本研究语音数据集在驾驶员路怒情绪以及非路怒情绪下进行采集,考虑到路怒情绪下驾驶员驾车具有一定的危险性,所以组织模拟驾驶实验。交互式模拟驾驶系统由力反馈方向盘、挡杆、驾驶座椅器以及Assetto Corsa软件构成,如图1。本实验对于实验人员条件要求以及音频数据的格式要求如表1。

图1 交互式模拟驾驶系统Fig.1 Interactive driving simulation system

表1 实验要求规范Table 1 Experimental requirements and specifications
1.2 实验内容
对40名实验对象按照从1~40的序号进行编号,对实验对象进行模拟驾驶训练,使其能够熟练操控模拟驾驶系统。在模拟驾驶实验开始之前,从网络上收集真实驾驶情况下行车记录仪记录的路怒视频中驾驶员的话语,各取频率出现最高的50句话,形成实验诱发情绪的文本材料[14]。
本文采用的情绪诱发方法为组合情感诱发方法[15]。一种为虚拟现实情感诱发法[16],另一种文本材料诱发法,能够辅助刺激巩固诱发的情绪,避免驾驶员在实验过程中由于情绪消散导致采集的实验数据不准确。
模拟驾驶实验中,利用虚拟的驾驶环境激发驾驶员的愤怒情绪,其具体的实现方式为:每次驾驶实验安排2名驾驶员,其中模拟驾驶座椅的实验者为主要测试者,辅助测试者的作用是在实验过程中,对主要研究对象的车辆做出强行变道、加塞、时快时慢驾车等行为[17],目的是诱发主要研究对象的愤怒情绪并保持。文本材料由平板显示在显示器下方,保持在驾驶员视线范围之内,辅助刺激主要研究者的路怒情绪。对于非路怒情绪采用音乐情绪诱发法,所用音频取自中国情绪刺激材料库中的中国情绪音乐材料库(CAMS)。
本实验是对40名实验对象依次进行实验,实验过程中,以主要研究对象诱发出的话语为次数基准,每个主要研究对象两类情绪诱发次数都不少于25次,采集到2 000份样本数据。最后,每个主要研究对象对自己的音频进行自我评价并标注情感类型。针对研究者可能存在不准确的主观评价,本研究利用听辨评判法保证数据集标注的可靠性,每条样本由5名未参与实验的人员进行评判。
1.3 类别标注
在本研究的评判方法中,采用度量值为1、3、5、7、9五个等级表达情感的强度,分别为极弱、较弱、一般、较强、极强。每个听辨人对数据样本都会给出一个评判的结果为评判值。本方法融合所有听辨人的评判结果,利用加权融合的准则得到每个样本的最终评判结果,并作为最终情感标注。公式如式(1):

式中,gr为听辨人评判结果的融合权重;
为情感样本;
R为听辩人总数,R=5;
r为听辨人。计算融合权值gr,先计算听辩人间的相似性ρpq,再得到一致度矩阵ρ,根据矩阵计算平均一致度ρˉr,归一化后即可得到,公式如下:

式(2)中,p、q为两个听辨人;
J为情感类别种类,J=2;
a为样本总数,a=2 000。本研究得到的语料库中有2 000个样本,其中路怒情绪样本和非路怒数据各1 000个。
2.1 频谱特征分析
本文以三维声谱图对驾驶员语音信号进行分析。声谱图从时间、频率以及能量强度三个维度描述信号语音信号的特征。图2给出了路怒和非路怒情绪下具有代表性的三维声谱图。

图2 路怒及非路怒情绪下的语谱图Fig.2 Spectrum of road rage and non-road rage
通过分析发现:驾驶员非路怒情绪下的频率能量集中分布于1 000~4 000 Hz,而路怒情绪下的频率能量集中分布于2 000~8 000 Hz,说明不同情绪的频率集中分布范围差异较大,从而能量分布和丰富度也相差较大,同时,反应出非路怒情绪下语音信号的能量变化相对平稳,相邻两帧信号之间的相似度高。
2.2 特征提取
2.2.1 预处理
预加重,根据上述频谱特征得出路怒情绪语音的频率能量大部分集中于2 000~8 000 Hz,频率高于2 000 Hz时会有10 dB的衰减,通过预加重能补偿高频能量,其函数如式(6):

其中,n为信号,μ∈[0.9,1],一般情况下取μ=0.95。
分帧加窗,由于音频的短时平稳性[18],可以对信号分帧处理,通常每秒取33~100帧,帧的长度一般为10~30 ms[19],同时采用交叠分段的方法,保持音频信号的连续性,用窗函数w(n)乘以原始信号s(n),形成分帧加窗后的音频信号为sw(n)=s(n)*w(n),本文采用汉明窗,窗函数公式如式(7):

式中,N为帧长,0≤n≤N-1。
2.2.2 短时能量

短时能量(short time energy)是指语音中的能量以帧数为单位的量值,假定当前为第i帧,则该帧音频信号的短时能量公式如式(8):其中,si(n)是第i帧预处理后的音频信号,N为帧长,E(i)为第i帧音频信号的短时能量值。如图3中所示,路怒情绪下的语音和非路怒情绪下的语音能量幅度相差明显,本研究取每个样本短时能量的最大值、最小值、均值、方差为特征参数。

图3 路怒及非路怒情绪下的短时能量Fig.3 Short-term energy in road rage and non-road rage
2.2.3 短时过零率
短时过零率(short time zero crossing rate)表示信号在波形中穿过横轴(零点)的次数,如图4所示,路怒情况下语音过零的次数明显多于非路怒情况,本研究取每个样本的最大短时过零率值为特征参数,短时过零率公式如式(9):

图4 路怒及非路怒情绪下的短时过零率Fig.4 Short-time zero crossing rate of road rage and non-road rage

式中,音频信号没有负值,sgn[*]是符号函数,如式(10):

2.2.4 MFCC的改进及提取
MFCC(Mel frequency cepstral coefficients)梅尔频率倒谱系数,是语音信号处理中最为常用的特征参数。传统MFCC中,通过求其一阶差分来描述不同帧数的动态变化,但是只能获得有限的动态特性,不能充分获取信号的动态特征。针对这个问题,本文利用经验模态分解(empirical mode decomposition,EMD)将音频信号按照时间尺度自适应分解,得到若干个本征模函数(intrinsic mode function,IMF)分量。改进MFCC特征提取流程如图5,具体步骤如下:
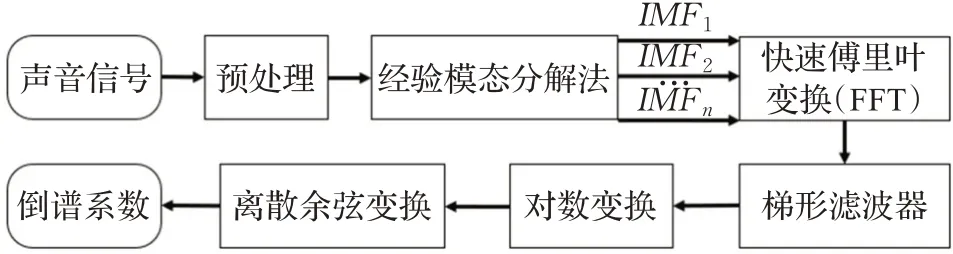
图5 改进MFCC特征提取流程图Fig.5 Flowchart of improved MFCC feature extraction
预处理后得到信号Si(n),其中下标i表示分帧加窗后的第i帧。
(1)确定语音信号Si(n)的局部极大值和极小值点,得到上下包络线z1(n)和z2(n),计算h(n),公式如式(11):

其中,m1(n)为上下包络线的均值。
(2)IMF分量有两个限制条件。在时域内:①过零点和极值点数目相等或最多差一个;
②上下包络线的均值为0。若h1(n)不满足限制条件,则将h1(n)重新作为待分解信号输入,重复上述步骤(1),直到满足限制条件,确定第一个IMF记为c1(n)。
(3)从S(n)中分离出c1(n)后得到r1(n),将r1(n)作为输入信号,重复步骤(1)、(2)。

其中,r1(n)代表语音信号的趋势分量,最终在满足rt(n)小于Sd后停止迭代,Sd为单调性函数,公式如式(13):

式中,T为信号时间长度,原始信号可以由P个IMF分量和趋势余项的和表示,如式(14):

对信号S(n)进行FFT变换并计算每一帧谱线能量,如式(15):

式中,i表示第i帧,k表示频域中的第k条谱线。传统MFCC采用三角滤波器组,三角形的特性使得每个通带的顶点与相邻通带的起点或终点相交构成交叠区域。导致交叠区域内信号的能量值会分配到相邻通带中。致使每个通带的输出在统计上不均等[20]。针对这个问题,本文选用梯形滤波器组,使得通带能量相互不影响,保证每个通带的输出在统计原则上均等。
在频谱范围内设置滤波器Hm(l),0≤m≤M,M为滤波器个数,一般滤波器个数为12~24,为了使得截取分析的数据更精确,本研究取M=23。每个滤波器具有梯形滤波特性,其中心频率为f(m),传递函数如式(16):为梅尔频率,是由实际频率根据

其中人耳听觉特性转化而来的频率尺度,公式如式(17),中心频率f(m)如式(18):

式中,f0为原始频率;
fh和fl分别为最高频率和最低频率。根据求出的每帧谱线的能量计算在每个通带中的能量,将能量取对数后计算DCT倒谱,得到最终参数,公式如式(19):

2.3 特征融合
本文采用改进MFCC与时域分析中的短时能量、短时过零率在特征层融合得到关键语音信号的新特征矢量,改进MFCC特征向量为T1=[FY1,FY2,…,FYR],共23维;
短时能量利用其最大值、最小值、均值、方差构成特征向量为T2=[EY1,EY2,EY3,EY4];
短时过零率的特征向量为T3=[HY1];
融合后特征向量T,如式(20):

融合特征向量构成如表2。

表2 特征向量Table 2 Eigenvectors
进行数据归一化。利用离差标准化方法,使结果值映射到[0,1]之间。函数如式(21):

式中,a′为原始数据。部分实验数据列举如表3。

表3 实验数据Table 3 Experimental data
本研究搭建了改进MFCC融合特征与FA-PNN组合的识别模型。根据驾驶员语音特性将频域MFCC参数改进后与时域中短时能量及短时过零率参数融合归一化后构成特征向量,利用FA优化PNN神经网络,构建识别模型,流程如图6所示。PNN是利用贝叶斯决策规则和高斯Parcen激活函数的一种前馈网络模型。其网络直接从训练范例中加载数据,无迭代过程,所以学习速度快,适用于需求实时性较高的场所,并且它具有径向基神经网络与概率密度估计原理的优点,在模式分类方面具有较为显著的优势,符合本研究的要求。

图6 识别模型流程图Fig.6 Flowchart of model identification
PNN网络有输入层、模式层、求和层和输出层。本研究特征参数为28维,即输入层神经元数为28,即数据维数d=28;
高斯核函数连接输入层和模式层,求得输入层和模式层中神经元之间的匹配程度。模式层输出为相似度,公式如式(22),在求和层做模式层输出的加权平均,公式如式(23),输出层取求和层中最大值作为输出的识别结果,公式如式(24)。


式(22)中xaj为第a个样本的第j个中心;
σ为平滑因子。式(23)中,vaj表示第a个样本为j类别的输出;
L表示神经元个数,L=28。
利用萤火虫算法优化平滑因子,平滑因子作为PNN神经网络的唯一的重要输入参数,其取值不同会直接影响到整个样本模式的概率密度函数的分布[21],对模型的识别性能有直接的影响。本文利用萤火虫算法对平滑因子σ进行寻优,萤火虫算法在局部和全局优化、鲁棒性能等方面有着独特优势,算法概念简单,流程清晰,需要调整的参数较少,收敛速度较快,同时搜索精度较高,更加容易实现。萤火虫群都受种群中亮度最大的萤火虫的吸引,并改变自身位置向其靠拢。将平滑因子σ随机初始化为向量σ=[σ1,σ2,…,σs],作为萤火虫的初始种群,随机分布位置。本研究中FA算法的目标函数定义为均方根误差(root mean square error,RMSE),如式(25):

式中,J表示PNN网络输出层的节点个数,等于类别数;
yi、ci分别表示PNN网络输出层的第i个节点的测试输出和期望输出。具体公式如下:
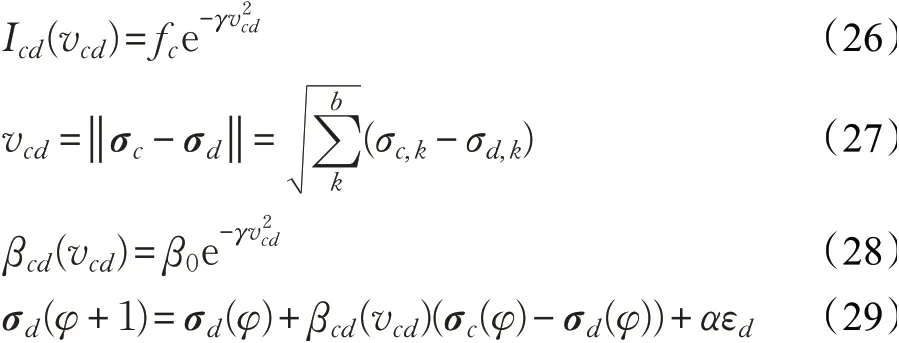
式(26)中,γ表示光吸收因子;
式(27)中,d为空间维数,σc,k为萤火虫c在d维空间中的第k个分量;
式(28)中,β0表示最大吸引力值;
式(29)中,φ表示迭代次数;
σc、σd分别为萤火虫c和d的空间位置;
α表示步长因子;
βcd为c对d的吸引力;
εd为[0,1]上服从高斯分布的随机因子。优化模型流程如图7所示,具体步骤如下:

图7 FA-PNN算法流程图Fig.7 Fa-PNN algorithm flow chart
步骤1初始化萤火虫的位置,将平滑因子σ作为萤火虫个体,σ=40,σ∈(0,4),初始化萤火虫位置。然后设定光吸收因子γ=1.0、步长因子α=0.2、最大吸引力值β0=1.0,设定当前迭代次数φ=1。
步骤2每个萤火虫的亮度Icd根据式(26)计算,吸引力βcd根据式(28)计算。亮度决定萤火虫的移动方向,吸引力决定移动距离。
步骤3式(29)更新计算萤火虫的位置。
步骤4在每个萤火虫的位置更新后,利用式(25)再次计算亮度。判断是否满足目标函数收敛或到达最大迭代次数,进行步骤5;
否则φ=φ+1,返回步骤3。
步骤5将得到的平滑因子σ作为PNN网络的参数进行训练,得到识别模型。
将样本导入模型中进行训练,FA-PNN中平滑因子的优化过程如图8所示,横坐标表示迭代次数,纵坐标表示训练样本的输出值与实际值的均方误差,从图中可以得出,当优化到第6代左右达到了局部最优,RMSE值为0.223,当达到33代时逃离局部最优,33代后值为0,表示PNN网络的训练样本的输出值与实际值的均方根误差值为0,最优时σ=1.1,即设定PNN网络参数平滑因子为1.1。

图8 FA-PNN的迭代过程Fig.8 Iterative process of FA-PNN
实验1由于汽车内设备存在一定的噪声,信噪比是指电子设备中信号与噪声的比例,信噪比越大噪声越小,以此来进行模型抗噪性能的评判。本研究针对不同信噪比情况下传统MFCC、改进MFCC、融合特征三种特征提取方法两类情绪样本进行识别正确率对比,如图9所示,图中表明,信噪比越高,三种特征提取方法识别正确率均越高,但随着信噪比的降低,传统MFCC正确率下降最快,改进MFCC正确率高于传统MFCC,融合特征参数正确率最优;
同时,改进MFCC特征在25~30 dB准确率快速提高,而传统MFCC在30 dB后才快速提高,证明了本特征提取方法相比传统方法具有较好的抗噪性,体现了较好的鲁棒性。

图9 不同信噪比正确率Fig.9 Accuracy of different SNR
实验2为了验证优化识别算法的优越性,本文利用融合特征处理后的相同数据,分别输入传统PNN和FA-PNN神经网络进行训练并测试,同时输入传统模型SVM、BP、KNN、LVQ进行对比分析。利用真阳性(true positive,TP)、真阴性(true negative,TN)、假阳性(false positive,FP)、假阴性(false negative,FN)计算准确率、精确率、F1-Score值、召回率对两种神经网络的识别结果进行评估,由于精确率和召回率之间存在相对性影响,所以引进F1-Score值,F1-Score值为精确值和召回率的调和平均,因此,该指标更加合理,得分范围为[0,1],得分越高,性能越好。公式如下:

两种神经网络测试结果的混淆矩阵如图10。根据图10(a)可知,对于FA-PNN神经网络,在100组的路怒情绪样本中,有98组样本识别正确,有2组样本被模型判为非路怒情绪;
在100组的非路怒情绪样本中,有88组样本识别正确,有12组样本被模型判为路怒情绪。根据图10(b)可知,对于PNN神经网络,在100组的路怒情绪样本中,有87组样本识别正确,有13组样本被模型判为非路怒情绪;
在100组的非路怒情绪样本中,有77组样本识别正确,有23组样本被模型判为路怒情绪。

图10 混淆矩阵Fig.10 Confusion matrix
从表4可以得出本研究的网络模型相比传统的PNN神经网络识别准确率提高了11个百分点,F1值相对传统PNN网络提高了0.104 7,PNN网络的识别准确率较低于LVQ网络,但FA-PNN网络相对于SVM、BP、KNN、LVQ模型平均识别准确率提高了约10个百分点,F1值也有所提高,说明本研究方法具有很好的性能。综上所述,改进MFCC融合特征与FA-PNN组合的识别模型识别效果要明显优于传统MFCC及常用识别模型。

表4 评估结果表Table 4 Evaluation results
驾驶员路怒情绪的识别研究对于降低道路安全隐患具有重大意义,语音信号处理技术为汽车主动安全驾驶预警研究提供了新方法。本文利用模拟驾驶系统采集驾驶员语音数据,根据语音的频谱特性,将时域中短时能量及短时过零率特征参数和改进MFCC特征参数融合构成特征参数向量,利用萤火虫算法优化PNN神经网络,实现驾驶员路怒情绪的识别。与传统MFCC特征参数及传统PNN神经网络进行了对比实验,结果表明,相同神经网络下,改进MFCC融合特征提取方法对于传统MFCC特征提取方法,在不同信噪比情况下识别正确率高而且抗噪性能更优。相同特征提取方法下,FA-PNN模型识别准确率为93%,相比传统PNN模型提高11个百分点;
F1-Score为0.932 8,相比传统PNN模型提高0.104 7,同时也明显优于其他传统识别模型。因此,本文所提出的识别方法在识别驾驶员路怒情绪方面表现优异。在本文中,只考虑了驾驶员的语音信息,后续研究中将进一步分析驾驶员语音特性及文本信息,进一步提高驾驶员路怒识别方法的精度和鲁棒性。








