基于AP-XDeepFM模型的广告点击率预测
时间:2023-02-15 12:35:06 来源:柠檬阅读网 本文已影响 人 
侯 娜 邵新慧
(东北大学理学院 辽宁 沈阳 110819)
互联网的出现和迅速发展使得广告有别于传统的媒体工具,借助互联网这个平台,在线广告应运而生[1]。目前,很多互联网公司的收益主要来源于广告,比如微博、谷歌等。广告的收入来源于用户点击广告,广告拍卖的效益取决于点击率(Click-Through Rate,CTR)预测的准确性。由于其广泛的价值和巨大的市场回报率,广告点击率问题成为学术研究的热点。
点击率是指某条广告点击次数与展示次数之比,反映了其内容的关注程度。高点击率意味着广告得到了精准的推送,有利于广告主产品的推广,增加平台方投放网站的访问量,给用户带来符合自己需求的信息,产生良好的搜索体验。精准的广告点击率可以实现广告主、平台方和用户的三方利益的最大化[2]。
广告点击率预测的发展初期,常用的研究方法是概率统计[3],但因数据稀疏,预测效果不理想。Richardson等[4]分别采用逻辑回归(Logistic Regression)和多元可加回归树(Multiple Additive Regression Trees,MART)方法进行预测,并采用拟牛顿法训练,结果表明Logistic模型的预测效果优于MART模型。Logistic模型简单但学习能力有限,不能捕获到非线性信息[5]。为挖掘非线性信息,Trofimov等[6]采用梯度决策树(Gradient Boosting Regression Tree,GBDT)方法进行广告点击率预测,GBDT能实现对特征的自动挖掘和组合,大量节省了人工成本。Facebook公司[7]提出将GBDT与LR模型相结合,将GBDT模型的结果作为LR模型的输入,重新进行训练,从而实现对广告点击率的预测。谷歌[8]提出FTRL(Follow The Regularized Leader Proximal)模型,针对LR模型设计独特的梯度下降方法,为防止过拟合加入正则化,同时提高了广告点击率预测的准确性。
为提高模型的预测性能,Rendle[9]提出了因子分解机(Factorization Machine,FM)模型,FM模型自动地捕获二阶交叉特征,解决了高维稀疏数据情况特征组合的困难。为解决当不同的域进行组合时,隐向量可能会表现服从不同分布的问题,研究人员基于FM模型提出了FFM[10]、AFM[11]、FwFM[12]等模型。
近年来,随着深度学习在自然语言处理、图像处理等领域取得不错的成果,引起了CTR预测研究领域的关注。Google研究人员提出Wide & Deep模型[13],该模型将浅层模型LR模型和非线性模型DNN(Deep Neural Networks)巧妙地融合,开创了嵌入的方法在CTR研究领域的先河。进一步地,Guo等[14]提出DeepFM模型,将Wide & Deep模型中的浅层模型替换为FM,并且使FM与DNN共享嵌入层的输出值,节省了人工提取特征的时间。Lian等[15]针对DCN[16]的不足,并结合DeepFM提出XDeepFM,该模型同时以显式和隐式的方式学习高阶的特征交互,并且特征交互发生在向量级。
XDeepFM模型中采用LR模型提取一阶特征,并且忽略了不同特征对于目标向量的重要性。本文对XDeepFM模型进行改进,提出基于AP-XDeepFM模型的广告点击率预测研究模型。在DNN的基础上加入Product层,并引入注意力机制,使得模型能够侧重于影响力大的特征且能进行更加细致的特征交互;
另外,采用FM模型,提取一阶特征和由一阶特征两两组合而成的二阶特征。
在CTR预测中,数据类型主要是分类特征,分类特征通常进行One-hot编码,会得到一个高维稀疏矩阵,带来维数灾难问题。传统的机器学习算法(如LR、SVM[17]等)不能很好地处理稀疏数据且忽略了特征之间的交互关系,FM模型是针对以上问题提出的一种高效的解决方案。
FM模型在进行特征组合时,默认每个交互特征发挥着同样的作用,实际上,每个交互特征的影响是不同的,AFM模型能够区分不同交互特征的重要性,提高模型的学习能力[11]。
借鉴图像识别中CNN扩大感受野的做法,在FM的基础上连接若干个全连接层,从而产生高阶的特征组合,加强模型对数据的学习能力,即FNN模型[5]。Qu等[18]认为在FNN模型中,特征经过嵌入层直接输入到DNN进行特征组合,也就是将特征进行加权求和这种方法不能充分捕获特征之间的相关性。因此,设计了Product层对特征进行更加细致的交叉运算。
考虑到FM模型不能捕获高阶特征之间的关系,FNN模型和PNN模型忽略低阶特征之间的作用,华为研究人员结合两个模型的优点,将FM模型和DNN结合起来联合训练,提出DeepFM模型,该结构比单一的学习模型预测性能表现得好。近年来,微软公司提出了一种能够显式和隐式地学习特征交互的融合模型xDeepFM模型,该模型将线性模型、CIN(Compressed Interaction Network)模型和DNN结合并行训练,CIN和DNN共享相同的输入向量,节省运行时间并提升模型的泛化能力。
表1介绍几种常见的CTR预测模型特性对比,分析发现,在模型结构上包括:单一浅层结构,如FM和AFM;
单一深层结构,如FNN和PNN;
浅层模型和(一个或多个)深层模型的融合结构,如DeepFM和XDeepFM。只有AFM模型赋予交叉特征不同的重要性。FM、AFM只能学习一阶特征和二阶组合特征,FNN、PNN只能学习高阶的交互特征,对于融合结构的模型,不仅能学习低阶特征也能学习高阶特征,但未考虑特征的重要性。XDeepFM模型采用LR的方式学习低阶特征,不能学习二阶交叉特征。基于上述分析,本文借鉴XDeepFM的主要框架进行改进,提出AP-XDeepFM模型,其特点是保留显式学习高阶特征的优点,并赋予交叉特征不同的重要性,通过引入Product层,对高阶特征进行更加细致的交互,通过采用FM模型,充分学习低阶特征,提高模型的预测性能。

表1 CTR预估模型特性对比
2.1 基本思想
AP-XDeepFM模型主要受到XDeepFM模型的启发,采用融合结构,其框架与XDeepFM类似,AP-XDeepFM模型主要分为三层。第一层是嵌入层,原始特征经过独热编码产生的高维稀疏特征经过嵌入层,将特征压缩映射为D维的稠密向量。第二层是由三个模块组合:FM模型、CIN模型和APNN模型。FM模型用于学习低阶的交互特征,CIN模型可以显式地学习高阶交互特征,APNN模型不仅考虑到特征重要性,而且能更加细致地进行隐式的特征提取。第三层是输出层,将FM、CIN和APNN的输出经过Sigmoid函数,采用Adam方法优化模型的参数,并进行分类得到最终的预测值。
2.2 FM模型
FM模型是在线性模型的基础上加入了二阶交叉项,弥补了线性模型忽略特征之间关系的缺憾。其模型为:
(1)
式中:n表示特征数量;
xi表示第i个特征的值;
vi表示第i个特征的隐向量;
<·,·>表示向量内积;
w0∈R。
在线性模型的基础上,加入二阶交叉项,不仅可以挖掘特征之间的关系,而且采用矩阵分解的思想来解决高维稀疏的问题,提高了模型的学习效率和预估能力。
2.3 APNN模型
目前为止,CTR预估研究问题的重心大多在于自动挖掘特征的交互信息,忽略了不同的交叉特征有着不同的重要性。比如对于用户关于NBA这则广告,性别为男且喜欢篮球的人群比性别男且家住上海的人群,更有可能点击,也就是说对于目标变量,前者比后者发挥的作用大。故将注意力机制引入模型中,使得不同的特征发挥着不同的重要性。
注意力机制[11]实质上是包含一个隐藏层的多层感知机,嵌入向量作为输入向量,使用ReLU函数对交互特征打分,最后使用Softmax函数对分数进行规范化处理。计算式如下:
(2)
(3)
式中:W∈Rt×D、b∈Rt和h∈Rt是模型参数,t是隐藏层节点数,D是嵌入向量的维度;
aij代表交互特征的重要性。
CTR预测研究的重点在于如何挖掘特征之间的相关性,DNN模型通过全连接的方法学习高阶特征,未充分捕捉特征之间的关系。本文借鉴PNN模型的思想,在DNN第一个隐藏层前加入Product层。该层是由线性部分lz和非线性部分lp构成,具体计算式为:
(4)
(5)
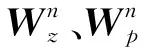
如图1所示,APNN模型是一个包含多个隐藏层的神经网络,不同于DNN,它采用单个隐藏层的神经网络搭建Attention层,并引入Product层增加模型的可解释性。每层采用ReLU函数作为激活函数,在第一层采用全连接的方式,如下:
(6)


图1 APNN模块的结构
2.4 CIN模型
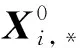
(7)

进一步地,通过sum-pooling操作将输出矩阵Xk压缩为向量,作为最终的输出,如:
(8)

2.5 AP-XDeepFM模型
如图2所示,FM模块和APNN模块的结合使用可以提高模型的泛化能力,CIN模块和APNN模块的结合能够充分学习交互特征,并引入注意力机制,加大重要交互特征的重要性,交互特征不仅能在元素级别上,也能在向量级别上进行显式和隐式的特征交互,提高模型的预测性能。
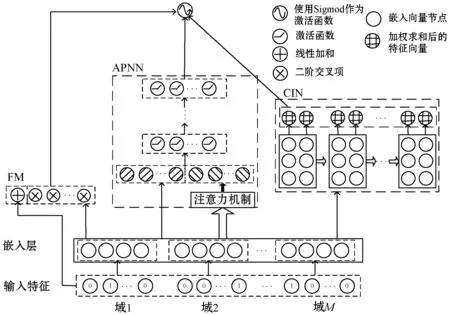
图2 AP-XDeepFM模型的结构
针对上述的AP-XDeepFM模型,我们设计了模型的具体训练步骤。
算法1基于AP-XDeepFM模型的CTR预估研究算法
输入:原始数据集。
输出:训练完的参数确定模型。
初始化参数:嵌入向量的维度D,CIN模型的层数,隐藏层节点,APNN模型的层数,隐藏层节点,迭代次数T。
1.fort=1 toTdo
//遍历每次迭代
2.获取特征xi,I={i|xi≠0};
3.通过嵌入层,每个特征映射到D维的嵌入向量;
4.if enter in FM then:
//嵌入向量输入到FM模型
if enter in APNN then:
//嵌入向量输入到APNN模型
lk=ReLU(Wklk-1+bk-1);
if enter in CIN then:
//嵌入向量输入到CIN模型
p+=[p1,p2,…,pk];
//输出预测结果
//使用Adam优化方法对参数进行优化
3.1 数据集
本文的数据集是2014年Kaggle竞赛中avazu公司提供的公开数据集。该数据集共有四千多万条,数据有23个特征和1个标签特征,其中正负样本比约是1 ∶4。在原始数据中按照分层抽样和随机抽样的方法抽取了100万条数据进行实验,并每天按不同的采样率进行采样,因此整体的正负样本比例与原始数据基本一致,不会对实验结果造成影响。
3.2 评价指标
为了检验模型的效果,本文采用了AUC和均方根误差这两种评价指标。
AUC(Area Under Curve)是刻画ROC曲线的分类能力[19]。AUC的取值在0到1之间,AUC的值越大,分类器效果越好,那么输出概率越合理,排序的结果越合理。所以,AUC直观地反映了广告的相对排序。
均方根误差(Root Mean Square Error,RMSE)用来衡量预测值与真实值之间的偏差,由于正负样本不平衡,精确度、准确率等评价方式不能准确地反映分类器的性能。由式(9)可以看出,RMSE能够很好地观察两个数据分布的差异性,RMSE越大,数据分布之间的差异越大,分类模型的预测效果越差,反之,RMSE越小代表模型的精确度越高。
(9)

3.3 实验结果及分析
本文算法代码是由Python 3.6软件编写,操作系统为Windows 7,内存4 GB,CPU频率为2.30 GHz。
本文选取前8天的数据作为训练数据,第9天的数据作为测试数据。在相同的实验环境下,将通过6组实验对AP-XDeepFM模型的性能进行对比,CIN中参数与xDeepFM模型中保持一致,对APNN中的重要超参数进行实验,讨论不同的超参数对结果的影响,获取最优的超参数组合。在实验中,使用AUC和RMSE对模型结果进行评估,实验分为5组。第1组实验讨论学习率对预估结果的影响;
第2组实验讨论APNN隐藏层层数对预估结果的影响;
第3组实验讨论隐藏层节点数对预估结果的影响;
第4组讨论激活函数对预估结果的影响;
第5组讨论随机失活率对预估结果的影响。第6组与典型模型进行对比。
3.3.1学习率实验
本节分析不同的学习率对预估结果的影响。学习率是一个重要的超参数,决定权重迭代的步长。在此实验中,采用搜索法,依次改变学习率为{0.1,0.01,0.001,0.000 1},记录不同学习率下模型的效果。根据表2中AUC和RMSE的结果可知,当学习率为0.001时,模型的预测性能最佳。
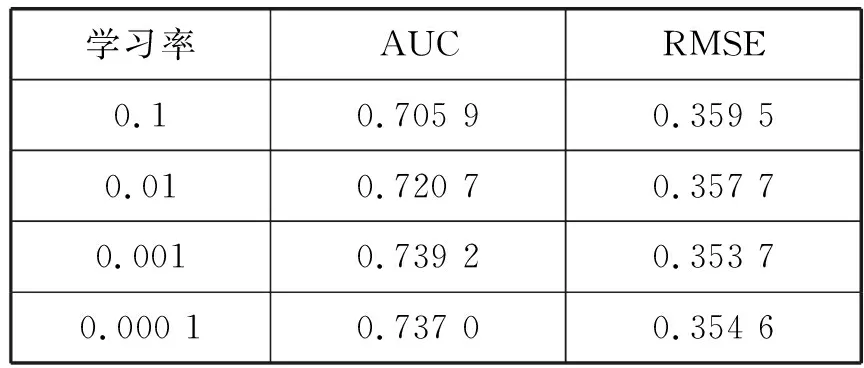
表2 不同学习率对性能的影响
3.3.2隐藏层数目实验
本节分析APNN网络隐藏层层数对预估结果的影响。在此实验中,根据3.3.1节的结果设置模型的学习率为0.001,假设各隐藏层节点数为100,隐藏层从1层逐渐加到4层,实验结果如表3所示。

表3 隐藏层数目对性能的影响
随着隐藏层数目的增多,模型的学习性能越高,CTR预估的准确性明显升高,说明模型对数据进行充分的学习,能够提取深层次的特征。当隐藏层数目大于3时,模型的性能迅速下降,说明过多地增加隐藏层的数目会导致模型出现过拟合现象。根据表3中AUC和RMSE两种评价指标的结果,选择隐藏层的数目为3。
3.3.3隐藏层节点数实验
本节分析APNN网络隐藏层节点数对预估结果的影响。考虑到每个隐藏层设置不同的节点数,会使实验变得很复杂,为简化实验,设置每层的节点数相同,依次改变节点数为{50,100,150,200},结果如表4所示。

表4 隐藏层节点数对性能的影响
可以看出,随着隐藏层节点数从50增至100时,模型的学习性能不断提升,CTR预估的准确性明显升高,模型得到很好的训练。当节点数目大于100时,模型的性能迅速下降,说明模型在训练集上学习过于充分,出现过拟合现象。根据表4中AUC和RMSE两种评价指标的结果,选择隐藏层节点数为100。
3.3.4激活函数实验
本节分析APNN网络激活函数对预估结果的影响。根据前几节实验的结果,设置学习率为0.001,隐藏层数目为3,节点数为100,采用ReLU和Tanh函数进行对比,根据表5中AUC和RMSE评价指标,ReLU函数比Tanh函数的表现略好。

表5 激活函数对性能的影响
3.3.5随机失活率的实验
本节分析不同的随机失活率对预估结果的影响。为防止模型过拟合,本文采用L2正则化和随机失活的方法。随机失活率为0.5表示在遍历网络中每一层时,会随机丢弃50%的节点。随机失活依次设置为{0.1,0.2,0.3,0.4,0.5},结果见表6。

表6 随机失活率对性能的影响
观察表6,使用随机失活的方法可以提高模型的表现,当p小于0.2时,模型的性能不断提升,可知若不使用随机失活,会导致模型过拟合,当p大于0.2时,模型的预估性能逐步下降,可能的原因是本文同时采用L2正则化和随机失活率的方法,影响模型的学习的能力。结合AUC和RMSE的表现,选择随机失活率为0.2。
通过使用网格搜索法,对学习率、隐藏层数目、隐藏层节点数、激活函数和随机失活率重要的超参数进行实验,讨论不同情况下模型的预估效果。通过分析AUC和RMSE两种评价指标,确定最优的超参数组合,即设置学习率为0.001,隐藏层数目为3,隐藏层节点数为100,激活函数为ReLU,随机失活率为0.2。
3.3.6与典型的模型进行对比实验
在相同的实验环境下,分别采用FM模型、基准模型(嵌入层+MLR)、PNN、DeepFM、XDeepFM模型和AP-XDeepFM模型进行对比实验,其中深度学习模型在层数以及每层节点数保持一致,优化方法采用Adam算法,学习率为0.001,嵌入向量的维度为10。结果如表7所示。

表7 不同模型的性能对比
实验结果分析:基准模型的预测效果优于FM模型,深度学习模型的预测性能优于基准模型。从AUC和RMSE指标分析,本文提出的模型AP-XDeepFM效果优于其他模型。相比于基准模型,其AUC值提高了0.006 6,RMSE值降低了0.001 3。实验结果表明了AP-XDeepFM模型能通过显式和隐式的方式,充分挖掘反映目标变量的高阶特征,还能自动学习二阶交叉项,丰富模型的特征,使用注意力机制,加大重要特征的权重,从而有效地提高了模型的学习能力和泛化能力。综上,本文改进的模型能够提高CTR预测性能。
为提高CTR预测效果,本文在XDeepFM模型的基础上进行改进,提出一种新的融合结构——AP-XDeepFM模型。从两个角度作为出发点,(1) 加大重要交互特征的权重,引入注意力机制;
(2) 挖掘特征之间的关系,引入FM自动捕获一阶以及由一阶生成的二阶特征,在DNN的基础上加入一个Product层,以便进行更加细致的学习高阶特征。通过实验讨论模型学习率、隐藏层层数、节点数、激活函数和随机失活率对模型性能的影响,并与几种典型的CTR预估模型进行对比。实验表明:该融合模型比现有的模型在AUC和RMSE上略有提升,可在元素级别和向量级别上显式和隐式地学习特征交互,也能捕捉到低阶交互特征,并使得重要交互特征发挥作用,有效地挖掘了高阶和低阶交互特征,提高了模型的预测性能。








