基于随机森林算法的煤层含气量三维精细建模*
时间:2023-01-26 08:40:11 来源:柠檬阅读网 本文已影响 人 
郭广山 郭建宏 孙立春 刘丽芳 田永净
(1.中海油研究总院有限责任公司 北京 100028;
2.油气资源与勘探技术教育部重点实验室(长江大学) 湖北武汉 430100)
煤层气是以吸附态为主的非常规天然气,历经几十年勘探开发实践,中国已取得显著成效。2021年全国煤层气地面抽采达到59.6亿m3,已建成沁水盆地南部和鄂尔多斯盆地东缘两个煤层气基地。近些年在深部煤层气、多薄煤层叠置煤层气藏等领域实现突破性进展。随着煤层气勘探开发进程,对煤层气储层精细评价和认知深度的需求愈发提高。在诸多煤层气储层参数中,含气性精细评价尤为重要。煤储层含气性贯穿于煤层气开发整个生命周期,从前期煤层气精准选区、适应性工程工艺设计、探明储量申报、产能建设以及低产低效井治理对煤层含气性认识均提出更高的要求。目前,行业内普遍采用参数井直接法确定含气量大小。为解决含气性非均质性强等难题,不少学者和专家创新提出诸多含气量间接方法,如多元回归分析法、基于测井数据含气量预测方法、KIM方程含气量预测方法、地震叠合反演含气量预测方法、核磁共振技术含气量预测方法、基于生产数据含气量预测方法等,这些含气量间接法有效的提高含气量的评价精度,适用于不同的勘探开发阶段,但受限于煤层气参数井含气量测试数量和参与计算数据的准确性[1-3]。随着大数据、AI技术、机器学习等新技术的兴起,不少学者已尝试将这些技术应用到煤储层评价中,目前机器学习含气量预测方法主要包括XGboost算法、随机森林算法、支持向量机算法和神经网络算法等[4-8]。煤层气现场工程工艺迫切需要深化煤储层含气量空间分布特征,而三维地质建模在常规油气储层方面已得到广泛的应用,但针对煤储层参数三维建模应用相对有限[9-14]。同时,未见有将机器学习和三维地质建模有机结合评价煤储层含气性。
为解决上述问题,笔者以沁水盆地南部柿庄南高煤阶煤层气田3号煤层为评价对象,依托38口煤层气参数井含气量测试数据和476口生产井常规测井资料,利用随机森林算法建立3号煤层含气量计算模型,并利用盲井进行可靠性验证,与实测值吻合度较好。在构建3号煤层构造框架基础上,利用油气行业成熟建模软件构建3号煤层含气量三维模型,精细刻画含气量空间分布规律,为区块滚动勘探和整体开发奠定基础。
柿庄南区块位于沁水盆地东南部(图1),是中国煤层气勘探程度较高的区块之一,区块面积388.0 km2。区域上沁水盆地南部属于沁水复向斜的南端,整体为一单斜构造。盆地西部主要发育宽缓的 NNE 向的次级褶曲,东部发育近南北向的次级山字形构造,断层不发育,地层倾角 5°左右,较为平缓。该区块具有东西分带的构造格局,整体呈东南高、西北低的构造格局。区内石炭系上统太原组和二叠系下统山西组是主要含煤层系。山西组为一套海陆过渡为主的三角洲沉积体系,其中3号煤层是该区开发目的煤层,煤层厚度分布稳定,主要在4.0~8.0 m,平均6.0 m;
中等埋藏深度,主要在400~1 020 m,平均750 m;
煤岩成熟度较高,Ro在2.5%~3.0%,为无烟煤三类;
参数井注入/压降试井测试结果显示3号煤层渗透率整体较低,主要在0.01~0.04 mD,属特低渗储层[15-16]。

图1 柿庄南区块区域位置图
2.1 随机森林方法原理及模型构建步骤
随机森林算法由Breiman于2001年提出[17],是一种并行式集成学习方法,即将多个个体学习器组合形成集成模型。随机森林方法是由同一类型的决策树模型组成,属于同质集成。随机森林算法中的每一个基学习器都是一个决策树模型。决策树节点分裂特征选择指标为Gini指数,相对于信息增益的对数化计算,其计算速度更快。为了防止模型出现过拟合或训练不充分导致的精度过低问题,将Bagging(bootstrap aggregation)思想引入至随机森林方法[2]。Bagging是典型的集成学习方法,而集成学习方法的基础就是Bootstrap方法。Bootstrap是一种抽样方法,其核心是对一整体样本进行有放回的抽取,该方法在数据分析中得到了较好的应用[3]。Bagging是基于bootstrap方法的并行式集成方法,所谓并行式方法是指个体学习器之间相互独立,不存在强依赖关系,可同时生成,即累积多个个体学习器的学习能力,能获得更优越的泛化性能,提高整体模型的预测精度和稳定性[17]。Bagging算法的流程如图2所示。

图2 Bagging算法流程图
本文评价煤层含气量的随机森林回归模型使用CART树,随机森林算法的流程如下:给定原始训练样本大小为N,参与建模的特征个数(测井曲线数)为M。

(1)
式(1)中:e为自然常数。可得到当样本足够大时,未参与决策树模型建立的样本数越趋近于原始训练样本数的36.8%,这一部分数据就叫做袋外数据(OOB,out of bag),一般可用于检验决策树模型效果。
2)基于子训练集建立决策树模型,首先从总体特征中随机选择m(m≤M)个特征,节点分裂时选取的特征通过计算m个特征的Gini指数。Gini指数越小,代表纯度越高,故Gini指数最小的特征即为该节点分裂的最佳特征,Gini指数具体计算公式为:
(2)
式(2)中:pl为样本属于第l类的概率;
L为目标分裂节点所含样本的总类别数;
A为m个特征中某个特征。通过该公式可以计算得到m个特征中Gini指数最小的特征。而在回归问题中,通过均方误差表征纯度,均方误差越小,代表纯度越高,故均方误差最小的特征即为该节点分裂的最佳特征。
通过上述原则,以二叉树的形式进行分裂至叶子节点,分裂结束的依据由设置的树的深度以及叶子节点包含最小样本数所定。
3)重复(1)、(2)步骤K次,即可得到K个子训练集以及对应的模型,这些相互独立的模型集成就形成随机森林模型。
4)利用随机森林分类模型对测试集进行预测时,每个决策树模型都会给出一个预测结果。对于回归类型问题,随机森林预测结果采取平均值方式,即K个基分类器预测结果的均值为随机森林预测结果。
可见,随机森林的“随机”体现在两方面:基分类器的训练数据的随机性及节点分裂特征选择的随机性,因此当基分类器较多时能实现原始训练数据的有效利用,且Bootstrap的思想能一定程度上解决样本数据分布不均衡的问题,这也使随机森林方法成为一种高效且实用性强的非线性算法。
2.2 含气量原始测试数据采集
针对目标区块,共收集到38口参数井,对参数井进行了井壁取心,各参数井在3号层采集的岩心样品个数为6~13组,收集对应参数井测井资料,包括井径测井、自然伽马测井、自然电位测井,电阻率系列测井(深、浅侧向)与三孔隙度系列测井(补偿密度、声波时差与补偿中子)等。以SZN1井为例,展示其含气量数据来源,该样品含气量测定遵照GB/T 19559-2004《煤层气含量测定方法》。SZN-1井中3号层共采集13个岩心样本用于解吸实验,岩心样本从取心密闭罐中送至实验室,结合实验测量了各关键参数,最终通过校正得到各井取心样品在空气干燥基状态下的含气量数值。
2.3 含气量参数样本数据库
1)基于2.2中收集到的目标区块3号煤层含气量实验数据,结合对应岩心样品的实验参数值,即实验室视密度值与实验室空气干燥基状态下的工业组分灰分值,通过比对上述值与实际补偿密度测井资料的响应变化趋势对岩心样本进行深度归位。
2)对各参数井间地球物理测井资料进行标准化处理,旨在消除因测井仪器与环境差异导致的测井曲线响应异常,具体做法为将参数井3号煤层上端的致密层视作标准层,以其中一口参数井为标准井,通过对比其他参数井致密层地球物理测井资料响应值与标准井之间的差异,确定加法因子后对地球物理测井资料响应值进行标准化处理,整个工作流程于CIFLOG软件中完成。
3)对测井资料进行扩径校正处理,由于煤层机械强度差易碎,使得钻井过程中易出现井壁垮塌即扩径现象,这一现象会使得地球物理测井资料响应值出现异常,本文对受扩径影响严重的测井系列进行扩径校正,利用多元回归模型完成了三孔隙度系列测井曲线及电阻率测井曲线的扩径校正。
4)根据深度归位后岩心样品的深度段提取对应的地球物理测井资料响应值,由于岩心样本并非为一深度点而是对应一深度段,因此对测井曲线响应值预处理时结合测井仪器实际采样间隔进行了多组数据提取以覆盖整个实验岩心段,并对样本数据组进行清洗,清洗目标可分为三类:①深度段对应测井曲线响应不全处,即由于部分岩心样本位于3号煤层起始段附近与终止段附近,这类样本点对应的测井曲线响应值往往只有理论响应值的一半(“半幅点”),不利于后续煤层含气量模型构建;
②夹矸段,在3号煤层下半段中存在非煤岩段,多为泥岩或炭质泥岩,这类岩心样本对应的地球物理测井资料中自然伽马测井系列与补偿密度测井系列响应值为异常高值,电阻率测井系列响应值为异常低值,故对这类岩心样本进行清洗;
③对本就不符合实验规范的岩心样品进行清洗。
综上,针对目标区块3号煤层含气量研究共获得689组煤层含气量与测井曲线响应数据用于煤层含气量模型构建。
2.4 煤层含气量模型构建与实例效果分析
结合本文实际研究内容,构建目标区块3号煤层含气量评价模型的实际步骤为:
1)将实际收集到的地球物理测井曲线响应与煤层含气量进行相关性分析,已有成果也表明测井曲线与煤层含气量的变化存在密切关系[5-7]。基于实际测井系列,选取自然伽马测井曲线,补偿密度测井曲线,声波时差测井曲线,补偿中子测井曲线和深、浅侧向电阻率曲线为敏感测井曲线,作为特征向量参与建立煤层含气量评价模型。
2)利用选取出的测井序列按照随机森林算法建模步骤进行模型构建,通过网格寻优与交叉验证的方法寻找最优的决策树个数与分裂特征数,同时测试模型的有效性。
3)根据探究得到的特征个数与回归子树个数进行建模,并用未参与建模的数据进行预测验证,以确保模型的泛化性。
在煤层含气量模型的构建中,受制于样本数量的限制,使得这一问题属小样本问题,随机森林算法中对小样本数据敏感的超参数为决策树个数与分裂特征数,树的深度在小样本数据中作用与决策树个数差异小,叶子节点数无须参与网格寻优[8]。因此本文对随机森林中分裂特征数与分裂特征数进行网格寻优,将分裂特征数的寻优步长设为1,决策树个数寻优步长设置为10,并同时引入交叉验证用于模型正确性判断,交叉验证是指将训练集数据等分成数份,每次留有一份数据作为验证,其余数据用于训练,利用验证部分的误差来判断模型的正确性,最终每一份数据都会得到一份误差结果,若每一份数据误差结果差距不大且稳定,则表明方法的正确性与有效性,本文使用的为十折交叉验证。将现有的样本数据组中随机抽取70%的数据作为训练集,剩余30%的数据作为测试集[18],训练集用于训练构建煤层含气量模型,测试集用于检验煤层含气量模型的正确性,并在此基础上,引入同工区中的其他新井作为验证数据来检验模型的泛化性与实用性。首先利用训练集对模型进行训练构造,图3a为随机森林方法的超参数网格寻优过程,经计算表明,分裂特征数为4且决策树个数为421时均方误差最低,并对这一参数配置进行交叉验证结果检查,如图3b所示,结合交叉验证结果误差表明,等分的十份数据各作为验证部分时误差低且无明显波动,即构建的模型效果展示无偶然性,也表明了该组超参数寻优结果的正确性。
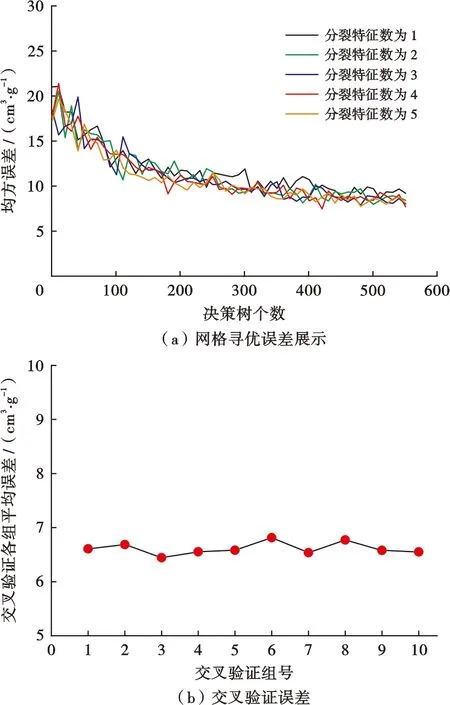
图3 随机森林构建煤层含气量寻优过程
将模型分别应用至测试集与验证集新井中,效果如图4所示,图4a为模型训练集回判结果,通过绘制交会图分析得到训练集数据准确性高,平均相对误差为4.51%,且所有样本点均在15%误差线内;
图4b为模型对数据测试集的应用效果,样本点中2%的数据落在15%误差线外,无误差异常高值点,整体样本数据均匀分布在零误差线两侧,平均相对误差为8.77%;
图4c为对新井数据进行处理后与实验数据绘制的交会图,通过误差分析分析,验证集数据分布于零误差线两侧,分析结果表明各组数据相对误差小于15%,平均相对误差为9.86%,使用效果与测试集上的表现相吻合。通过上述分析,训练集的结果表明了模型建立的有效性,表明模型对数据学习利用的完整性,测试集的结果表明了模型的正确性,验证集的结果表明了模型具有泛化性与实用性。

图4 随机森林构建煤层含气量模型效果展示
此外,图5展示了一口验证集新井的评价结果,随机森林方法计算得到的含气量曲线与对应深度的岩心样本实验含气量结果在数值上吻合程度高。这说明了随机森林方法在煤层含气量模型构建的可行性与正确性,也表明了利用随机森林方法结合地球物理测井资料评价得到的煤层含气量模型可被推广应用于煤层含气量三维精细建模。

图5 随机森林方法构建的煤层含气量模型在验证集新井上的应用效果
煤储层含气量三维建模将煤储层含气量测试技术、计算机算法和测井学等多门学科有机结合,最大程度精细刻画含气量空间分布特征,有效支撑区块煤层气滚动勘探和整体开发[19]。
笔者依托参数井岩心含气量测试数据和随机森林算法含气量预测曲线,利用常规油气成熟三维建模软件,在3号煤层层序建模的基础上构建含气量三维模型,精细刻画3号煤层含气量空间分布特征。
3.1 三维地质模型网格设计
依据研究区面积和参与本次建模的煤层气井平面分布情况,对3号煤层三维地质建模做网格化处理,平面网格设置为100 m×100 m;
根据研究区3号煤层厚度大小及稳定性情况,垂向网格控制在0.5 m,三维地质模型的网格为:X方向为111个网格,Y方向为146个网格,Z方向为19个网格,网格总数为111×146×19=307 914个。
3.2 构造模型建立
构造模型是实现煤储层属性精细建模的前提。本次研究区勘探开发程度较高,参与此次建模的井数多且分布均匀,为实现精细建模提供资料基础。将参与建模煤层气井基础信息、含气量测井曲线、煤层顶、底面海拔数据导入,生成3号煤层顶面和底面构造两个层面,构建煤层结构体和层序建模,实现3号煤层构造建模。结果显示,山西组3号煤层厚度在2.5~14.0 m,平均6.0 m;
区块具有东西分带的构造特征,整体呈东南高、西北低的构造格局(图6)。

图6 山西组3号煤层三维构造模型
3.3 含气量属性建模
在三维构造模型基础上,利用基于随机森林算法含气量预测曲线,构建3号煤层含气量三维模型。具体步骤为:①将随机森林算法计算得出的含气量曲线导入数据库;
②选择随机森林算法计算的含气量曲线,在指定研究区内进行煤层气井筛选,确定参与建模的煤层气井和含气量曲线;
③采用序贯高斯算法,利用高斯模型构建含气量属性三维模型;
④利用变差函数分析对含气量在空间上的连续性及各方向异性进行评价。模型结果显示:区内3号煤层含气量分布在6.4~25.4 m3/t;
高含气区分布在区块西部和北部,纵向上在距顶面1.0 m和底面2.0 m范围内发育两个高含气层段(图7)。煤层含气性对煤层气勘探开发、储量评估和产能建设具有决定性指导作用,该模型将对煤层气精准选区、水平井轨迹设计、射孔层段优选以及低产低效井综合治理具有重要的指导意义。

图7 山西组3号煤层含气量三维模型
1)利用随机森林方法结合地球物理测井资料可以有效评价煤层含气量,随机森林方法因Bagging思想能平衡数据样本分布不均的问题使得这一模型针对含气量的评价效果无偏差,且利用网格寻优与交叉验证相结合的超参数寻优方式能保证模型的正确性与有效性,构建的煤层含气量模型具有泛化性与实用性,为含气量精细三维模型的构建打下坚实的数据基础。
2)机器学习与三维地质建模技术高度融合是实现含气性空间表征的有效途径之一。随机森林算法在含气量计算中的应用能有效克服样本数少且非均质性强等问题。对于不同类型煤层气田适用的机器学习方法会有所不同,需根据具体情况来确定。含气性空间表征的准确程度取决于含气量机器学习曲线的数量和参与计算井分布情况,随着样本数和参与计算井数的增加以及分布相对均匀,含气量三维地质模型愈发精确。该方法对于煤层气精准选区、水平井轨迹设计及钻探、压裂射孔优选具有较好指导意义。
猜你喜欢 气量煤层气测井 本期广告索引测井技术(2022年3期)2022-11-25新疆首批煤层气探矿权成功挂牌出让矿山安全信息(2022年29期)2022-11-252025 年全国煤层气开发利用量将达100 亿m3煤化工(2022年3期)2022-11-21高强度高温高压直推存储式测井系统在超深井的应用石油钻探技术(2022年5期)2022-10-17延长油田测井现状与发展前景能源与环保(2021年4期)2021-05-07做人要有气量,交友要有雅量新传奇(2020年40期)2020-10-23MATLAB GUI在表征煤层气解吸行为过程的应用软件(2020年3期)2020-04-20气量可以学习吗意林·全彩Color(2019年8期)2019-11-13王旦的气量小天使·五年级语数英综合(2019年6期)2019-06-27气量三层次领导文萃(2017年10期)2017-06-05







