基于改进的K-means聚类算法的学生成绩分析
时间:2023-01-23 13:30:04 来源:柠檬阅读网 本文已影响 人 
张 云
(安徽开放大学 教务处,合肥 230022)
安徽开放大学的主要教育形式是现代远程教育。近年来随着互联网技术的发展,线上教学模式在开放教育中的应用日益广泛。与普通高校的全日制学生不同,开放教育学生来自各行各业,需要平衡工学矛盾;
学生年龄跨度比较大,学习目的和学习需求呈现多元化。线上学习可以随时随地进行,学生可以根据自己学习情况重复观看课程视频,也可以利用碎片时间进行学习。线上学习为开放教育的学生提供了非常便利的学习方式[1],因此学生的线上学习需求旺盛。但是,线上学习也存在一些缺点,如课堂上师生间缺乏交流互动,无法及时了解学生对知识点的掌握情况,无法直观了解学生处于哪个年龄层次等。这些信息的缺乏影响了教师对课程教学效果的判断以及制定合适的教学计划。
学生的考试成绩是检查学生学习情况以及检验教师教学成果的重要途径。通过开放大学的教务系统可以查询学生的学习成绩,包含形考成绩、卷面成绩以及综合成绩。为了解线上教学模式的效果,了解不同年龄阶段学生线上课堂知识点的掌握情况,深层次挖掘成绩数据里面所隐藏的有价值信息十分必要。本文对不同年龄段学生期末考试相关成绩进行聚类分析,挖掘学生线上学习成效与学生年龄之间的关系,为教师针对不同年龄段的学生制定个性化教学方案提供理论依据,从而进一步提升开放教育的教学质量。
K-means算法是一种有效的聚类划分方法 ,其主要思想是:在给定K值和初始簇中心的情况下,把数据对象划分到距离其最近的簇中心所代表的类簇中,所有数据对象分配完成之后,根据一个簇内的所有数据对象重新计算该类簇的中心,然后再迭代进行分配和更新簇内中心的步骤,直至簇内中心点的变化很小,或者达到指定的迭代次数[2]。
假定D={X1,X2,X3,…,Xn}是具有n个数据对象集合,其中每个数据对象都具有m个维度的属性。K-means算法就是以欧式距离作为衡量数据对象间相似度的指标,将数据样本D中n个数据对象依据数据对象之间相似性划分到k个类簇C1,C2,C3,…,Ck中,其中1≤k≤n。集合中每个对象都划分到与其距离最近的簇内中心所在的类簇中[3-5]。
K-means具体算法流程如下[6-8]:
(1)从数据对象D中随机选取K个对象作为初始类簇中心。
(2)根据公式(1)计算当前每个簇内数据对象到簇中心的欧式距离:
(1)
式(1)中Xi表示第i个数据对象,1≤i≤n,Cj表示第j个类簇中心,1≤j≤k,Xit表示第i个对象的第t个属性,Cjt表示第j个类簇中心的第t个属性,1≤t≤m。
(3)依次比较每个数据对象到簇中心的距离,将数据对象划分到距离最近的簇内中心的类簇中,得到k个类簇{S1,S2,S3,…,Sk},根据公式(2)重新计算新的类簇中心,
(2)
式(2)中Cl表示第l个类簇中心,1≤l≤k,|Sl|表示第l个类簇中数据对象的数量。
(4)重复步骤(2)和(3)直至类簇中心不变或达到指定的迭代次数。
(一)数据选取
数据的质量决定了聚类模型预测结果,其涉及很多因素,比如数据的真实性、时效性、完整性等[9]。现实中,我们拿到的真实数据可能由于数据收集过程中的主客观因素,而包含了部分无效信息、失真信息或异常数据,这些数据都是造成模拟训练结果与实际情况不相符的主要因素。
从开放大学教务系统中选取了安徽开放大学计算机科学与技术本科班软件工程课程2021年春季学期期末考试相关成绩进行分析,所选成绩样本数据来自全省所有选择该课程的学生,共计样本成绩数据240条。通过K-means算法与加权K-means算法分析结果进行比较,选择更适用于进行成绩分析的方法,分析不同年龄层次的开放教育学生的考试成绩与学生学习效果之间的关系。为了分析结果更加真实有效,我们选取含有成绩数据的学生成绩进行模拟训练。
(二)K值的选取
初始聚类数K值的选取,若偏离真实值,则会直接影响数据样本聚类的效果。本文通过“手肘法”来确定初始聚类数K值。“手肘法”是通过聚类数K与误差平方和(SSE)之间对应的关系,在K与SSE的关系中,我们可以通过观察拐点来确定K值。随着K值的增加,并且K值未达到真实值之前,SSE值下降的幅度会很大,数据对象的聚类会更加明显,数据对象之间的聚合程度会逐渐增大;
当K值达到聚类数的真实值时,SSE值的下降幅度会迅速减缓;
而当K值大于真实值并且继续增加时,SSE值会逐渐趋于平缓[9-10]。
K值确定步骤:
(1)通过式(1)确定每个类簇中的对象到簇内中心的欧式距离;
(2)计算每个类簇内的误差平方和;
(3)计算当前数据对象的总误差和;
(4)K为K+1时,重复计算当前数据样本对象的SSE值,确定K值。
误差平方和公式:
(3)
式(3)中K为聚类的数量,X为当前簇Ci中的数据对象,ci为当前簇Ci的中心。
使用SPSS软件的K聚类分析功能对课程成绩进行聚类分析,聚类数K从2增加到11的聚类结果如图1所示,可以看出曲线在K=7时有明显的拐点,即“手肘”,根据“手肘法”可以确定该数据的真实聚类数应为7。
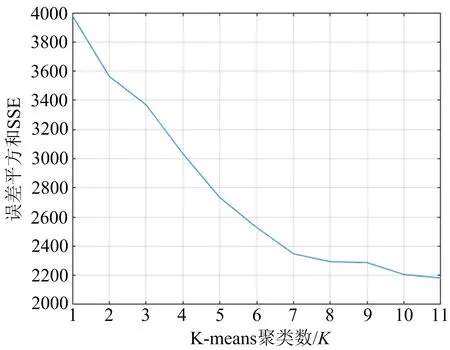
图1 手肘图像结果
(三) K-means权重选取
从公式(1)可知,如果数据对象的某一属性变化范围大,那么在计算聚类成员到聚类中心的距离时,它的权重就会相对较高,最终会导致聚类中心更偏向该属性。为更直观说明这一问题,本文实验使用K-means算法对学生的期末考试卷面成绩和年龄进行聚类分析,结果如图2所示。

图2 K-means聚类算法成绩分析结果
从图2可以看出聚类有明显的不合理之处,样本数据的聚类中心倾向于成绩属性,在年龄属性上跨度较大。以“★”所代表聚类为例,该聚类左右两侧存在明显的界限,该聚类中右侧的样本数据更应该与“•”所代表的聚类归为一类。这是因为在成绩与年龄二维坐标中,成绩的取值范围是0~100,而年龄的取值范围为20~51。成绩的取值范围约为年龄取值范围的3倍,由式(1)可知,使用普通K-means算法进行聚类分析时,成绩维度在欧氏距离中占比更重,聚类中心会倾向于成绩属性。
通过式(1)计算欧氏距离时,若某一个属性的取值范围明显大于其他属性,那么该属性在欧氏距离中比重就会偏重。为了消除这种现象,可以将样本数据的每个属性调整到相同的取值范围,即在进行聚类分析前,给每一个属性乘上不同的系数at得到X′i,其中X′i={a1Xi1,a2Xi2,…,at-1Xi(t-1),atXit}。
(4)
公式(4)中st为第t个属性的取值范围。
故本实验加权后采用的欧氏距离计算公式为:
(5)
使用公式(5)作为欧氏距离公式相当于对每个属性赋以不同的权重,使用加权后的算法重新对包含学生成绩与年龄的样本数据进行聚类分析。结果如图3所示。

图3 加权的K-means聚类算法成绩分析结果
从图3可以看出,样本数据不再倾向于年龄属性的聚类,“★”所代表的聚类不再有明显的界限,聚类结果更加科学。
通过图2和图3中K-means算法和加权的K-means算法聚类结果对比可知,对于相同的成绩样本数据对象,加权的K-means算法聚类比普通的K-means算法聚类效果更加明显且更加合理。
根据前文结论可知,使用加权K-means算法能更加准确探索学生的年龄与期末考试的成绩是否存在关联。前文为方便直接观察两种聚类结果,文中只选取了学生的综合成绩与年龄二维样本数据进行聚类分析。为了获取学生的年龄、形考成绩、卷面成绩和综合成绩的内在关联,使用加权的K-means算法对样本数据进行聚类分析,样本数据包含学生年龄、形考成绩、卷面成绩、综合成绩四个维度,聚类分析后,结果如表1~3所示。

表1 最终聚类中心
从表2最终聚类中心间的距离可以看出最小的间距为18.986,聚类中心之间的距离较大,聚类结果较好。
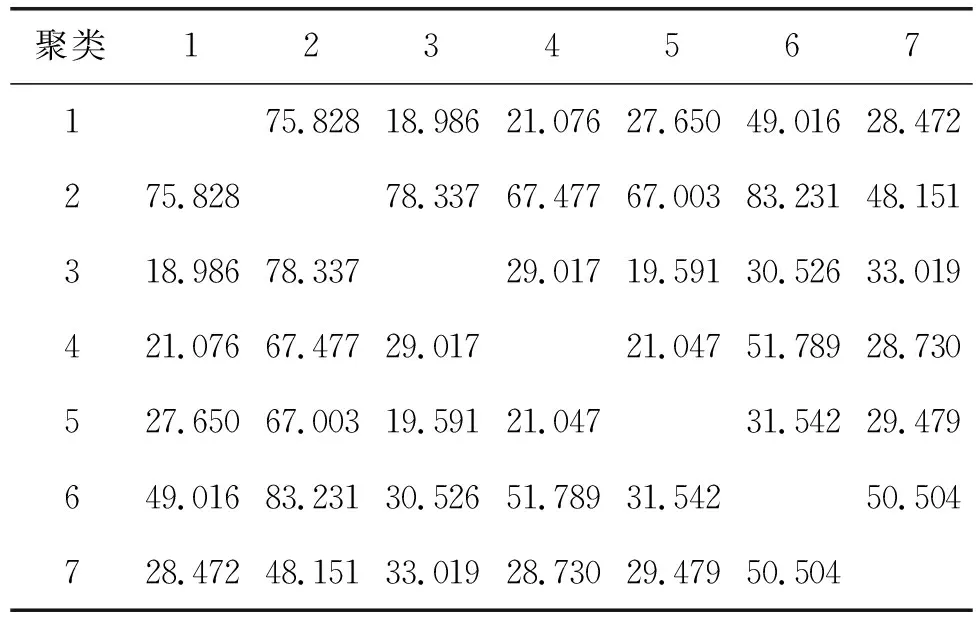
表2 最终聚类中心间的距离

表3 聚类案例数
对表1最终的聚类中心进行分析可以发现,聚类1和聚类4对比可以看出这两个聚类学生较年轻,形考成绩较高,但卷面成绩和综合成绩差距较大,说明这个年龄段的学生学习时间比较充裕,有较多的时间完成课后作业。但卷面成绩有高有低,说明他们对知识的掌握程度有好有坏,授课老师可以针对这个年龄段的学生加强知识点的巩固。
聚类2和聚类7中的学生年龄相仿,但形考成绩都不理想,说明这类学生忽视平时作业的完成,可能是因为这个年龄段的学生平时学习时间少,老师可以在平时作业方面多给予指导,提升他们的形考成绩。
聚类3和聚类5中学生的年龄相仿,三项成绩都很平均,说明这类学生学习有一定的主动性,老师可以从平时的作业中提前了解他们的学习情况。如果他们平时的作业完成度好,那么他们的期末考试卷面成绩也不会差;
如果他们的平时成绩完成得不好,老师可以适当地对他们提出要求。
聚类6中的三项成绩都较高且较为平均,说明在这个年龄段的学生既有一定的时间完成课后作业,同时也注重知识点的掌握与巩固,可能是因为这个阶段的学生对知识更加渴望,老师在授课过程中可以适当地降低对他们的关注,将精力更多地放在其他学生身上。
加权的K-means算法适合用于样本数据对象各个维度的数据范围相差较大或明确知道某个维度的数据更重要的场景。使用加权的K-means算法可以更好分析学生的成绩与年龄的相关性,获得更加准确的结果,为教师提供更多的学生数据信息。通过对聚类结果的分析,教师可以更加了解每个年龄段学生优势和弱点,有的放矢,因材施教,更加精准地指导每个学生的学习。在花费同等精力的同时,更加高效地提升学生的整体学习效果。
猜你喜欢 聚类对象年龄 变小的年龄小猕猴智力画刊(2022年9期)2022-11-04晒晒全国优秀县委书记拟推荐对象廉政瞭望·下半月(2021年5期)2021-07-20判断电压表测量对象有妙招中学生数理化·中考版(2020年10期)2020-11-27面向WSN的聚类头选举与维护协议的研究综述现代计算机(2018年27期)2018-10-25攻略对象的心思好难猜意林(2018年3期)2018-03-02改进K均值聚类算法舰船电子对抗(2017年6期)2018-01-11年龄歧视小学生作文选刊·低年级版(2017年2期)2017-03-06算年龄小学生导刊(低年级)(2016年8期)2016-09-24基于Spark平台的K-means聚类算法改进及并行化实现互联网天地(2016年1期)2016-05-04基于加权模糊聚类的不平衡数据分类方法现代计算机(2016年17期)2016-02-28







