视觉语言多模态预训练综述
时间:2022-12-02 20:50:04 来源:柠檬阅读网 本文已影响 人 
张浩宇,王天保,李孟择,赵洲,浦世亮,吴飞*
1. 浙江大学计算机与科学技术学院,杭州 310013;
2. 杭州海康威视数字技术股份有限公司,杭州 310051
深度学习(deep learning, DL)方法在计算机视觉(computer vision, CV)、自然语言处理(nature language processing, NLP)以及多模态机器学习(multimodal machine learning, MMML)的各个具体任务上取得了令人瞩目的进展,但不同任务之间需要使用专有的数据进行训练,大量的重新训练使得时间和经济成本显著增加。预训练模型(pre-trained model, PTM)与微调(fine-tuning)相结合的范式旨在缓解这一困难,预训练模型首先在大规模通用数据集上利用自监督为代表的方式进行预训练,使得模型在迁移至下游任务之前学习到通用的表征,然后在小型专有数据集中进行微调得以获取特定任务知识(Yosinski等,2014)。这一方法在很大程度上打破了各具体任务之间的壁垒,在避免重新训练所造成的资源浪费的同时,对下游任务的性能起到促进作用。
Transformer(Vaswani等,2017)是当前预训练模型使用最广泛的基础结构,其因为在处理长距离依赖关系方面的优势,最初在机器翻译方面取得了成功,随后广泛用于NLP领域。GPT(generative pre-training)(Radford等,2018)采用Transformer作为模型预训练的基础结构在大规模语料库中进行预训练,将学习到语言知识的参数模型用于具体任务,实验中12个下游的NLP任务性能取得了显著提升。BERT(bidirectional encoder representations from transformers)(Devlin等,2019)采用了双向语言模型进行预训练,在语料中随机对15%的单词令牌(token)进行掩码,要求模型可以预测出原有单词令牌,此外还进行了句子预测任务,实验中11个下游的NLP任务性能取得了提升。随后的若干工作(Dong等,2019;
Liu等,2019a;
Radford等,2019;
Shoeybi等,2020;
Zellers等,2019b;
Yang等,2019;
Brown等,2020;
Lewis等,2020;
Raffel等,2020;
Zhang等,2020b,2021b;
Fedus等,2022;
琚生根 等,2022;
强继朋 等,2022)证明预训练的语言模型能够普适地对下游任务性能起到促进作用。受到NLP领域的启发,CV方面的研究者也相继开展基于Transformer的视觉预训练工作。ViT(vision transformer)(Dosovitskiy等,2021)将图像的补丁块(patch)作为序列输入Transformer进行预训练,克服Transformer结构难以处理图像输入这一困难。CLIP(contrastive language-image pre-training)(Radford等,2021)将自然语言作为监督以提升图像分类效果,使用对比学习(contrastive learning, CL)方法促进图像和文本的匹配能力。MAE(masked autoencoders)(He等,2021a)将NLP中常用的自监督方法用于CV预训练,其通过训练自编码器,预测经过随机掩码而缺失的图像patch,从而高效、准确地进行图像分类任务。
人类最具有抽象知识表达能力的信息为语言信息,而人类获取的最丰富的信息为视觉信息,上述工作分别在这两种模态上开展预训练并取得成功。视觉语言任务(vision-and-language task)(Pan等,2016a;Tapaswi等,2016;
Yu等,2016a;
Pan,2016b;
Jang 等,2017;
Maharaj等,2017)是典型的多模态机器学习任务,其中视觉和语言两种模态的信息互相作为指引,需让不同模态的信息对齐和交互,进行视觉语言预训练(visual-language pre-training, VLP)工作并提升模型在下游的视觉问题回答(visual question answering, VQA)(Johnson等,2017)、视频描述(video captioning)(Zhou等,2018a,b,2019)和文本—视频检索(image-text retrieval)(Wang等,2016,2019;
Song和Soleymani,2019)等任务上的效果。视觉语言任务存在着很大的挑战。其中一个难点是,使用何种易于大规模获得并且含有大量通用知识的多模态数据来源,以构建训练数据集;
另一个难点是,如何通过有效的机制,将属性相差巨大的不同模态的信息进行统一训练。
对于以上问题,一方面,当前的主要方法通过获取来自互联网的图文对、包含语言描述的教学视频、附带字幕的影视剧以及其他各类视频等视觉语言多模态数据,制作涵盖广泛常识信息的大规模预训练数据集;
另一方面,设计能够处理多种模态信息的神经网络模型,通过以自监督为代表的方式进行大规模数据训练,对数据集中不同模态的信息进行提取和融合,以学习其中蕴涵的通用知识表征,从而服务于广泛的相关下游视觉语言多模态任务。
当前对预训练模型的综述工作主要集中在单模态(Qiu等,2021;
Kalyan等,2021;
Min等,2021;
陈德光 等,2021;
韩毅 等,2022),部分工作梳理视频—文本多模态类型(Ruan和Jin,2021),但较为全面的VLP综述工作(Chen等,2022)相对较少。本文梳理最新视觉语言多模态预训练模型的相关研究成果,首先对VLP模型常用的预训练数据集和预训练方法进行简要介绍,然后在介绍基础结构之后对VLP模型按视觉输入来源进一步分类,介绍目前具有代表性的图像—文本预训练模型和视频—文本预训练模型,并根据模型结构不同分为单流和双流类型,重点阐述各研究特点,对不同VLP预训练模型在主要下游任务上的性能表现也进行了汇总。最后对目前研究面临的问题进行探讨。
1.1 预训练数据集
在各类预训练任务中,模型性能受预训练数据集质量的影响显著。为了获取通用的多模态知识,视觉—语言预训练任务主要使用带有弱标签的视觉—语言对进行模型训练。图像—文本任务主要为图像及标题、内容描述和人物的动作描述等。类似地,视频—语言预训练数据集包含大量的视频—文本对,其标签来源包括视频中的文字描述以及由自动语音识别(automatic speech recognition, ASR)技术获得的文本信息等。部分模型为针对性提升某一模态的表征提取能力,在多模态预训练之外还进行单模态数据集进行预训练,使用图片数据集与纯文本数据集。
预训练中常用的公开数据集有,图文数据集SBU(Ordonez等,2011),Flickr30k(Young等,2014),COCO(common objects in context) Captions(Chen等,2015),Visual Genome(VG)(Krishna等,2017b),Conceptual Captions(CC, CC3M)(Sharma等,2018)和Conceptual 12M(CC12M)(Changpinyo等,2021),VQA(visual question answering)(Antol等,2015),VQA v2.0(Goyal等,2019),Visual7 W(Zhu等,2016),GQA(Hudson和Manning,2019);
视频数据集TVQA(question-answering dataset based on TV shows)(Lei等,2018),HowTo100M(Miech等,2019),Kinetics(Kay等,2017),Kinetics-600(Carreira等,2018),Kinetics-700(Carreira等,2019),YT-Temporal-180M(Zellers等,2021),WebVid-2M(Bain等,2021);
单模态图片数据集COCO(Lin等,2014),OpenImages(Kuznetsova等,2020),文本数据集BooksCorpus(Zhu等,2015)以及English Wikipedia。数据集信息汇总如表1所示,以下对代表性的数据集做进一步介绍。
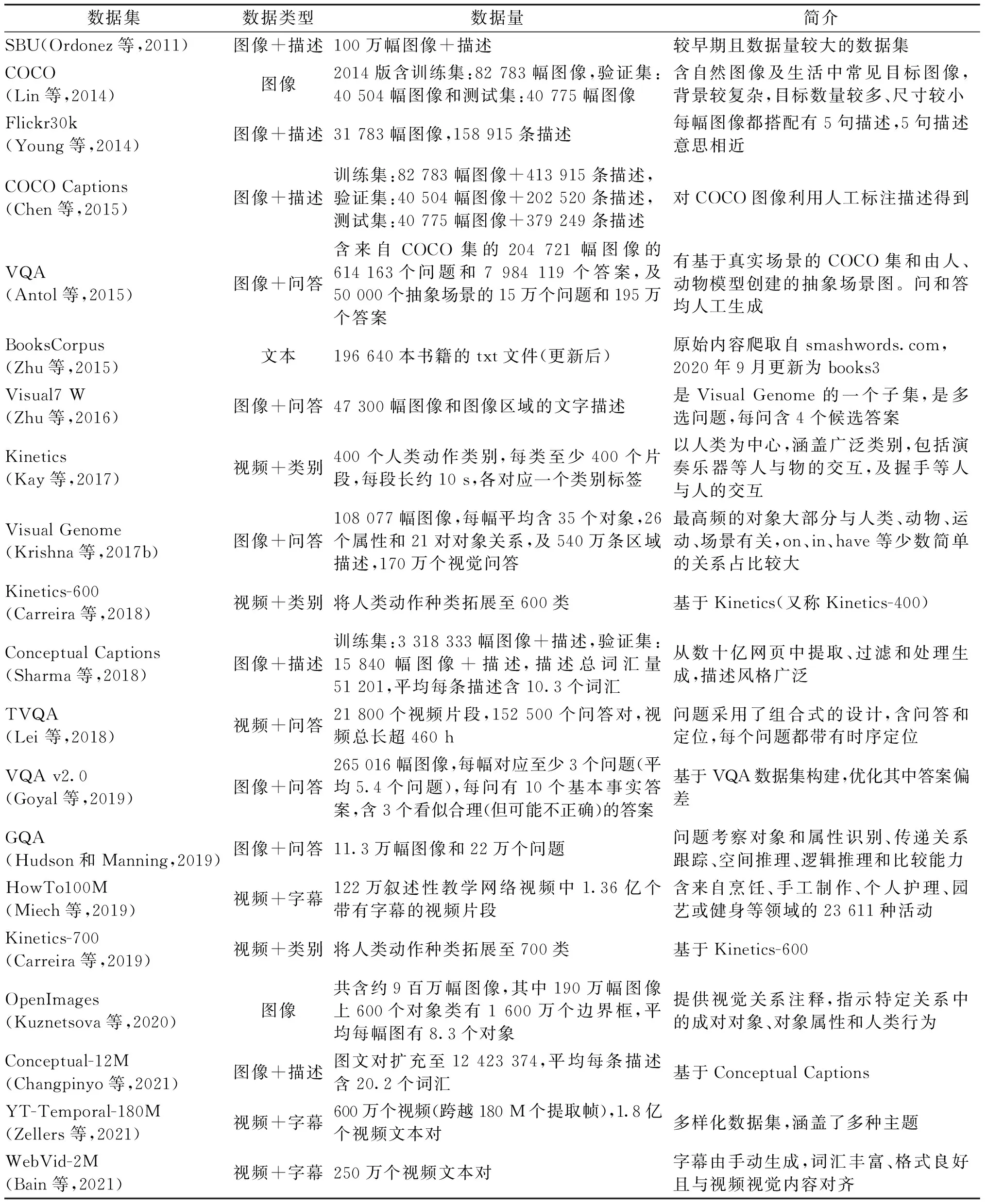
表1 视觉—语言多模态预训练数据集Table 1 Multimodal pre-training datasets
SBU(Ordonez等,2011)数据集:SBU是较为早期的大规模图像描述数据集。收集数据时,先使用对象、属性、动作、物品和场景查询词对图片分享网站Flickr进行查询,得到大量携带相关文本的照片,然后根据描述相关性和视觉描述性进行过滤,并保留包含至少两个拟定术语作为描述。
COCO(Lin等,2014)数据集:COCO是一个大型、丰富的物体检测、分割和描述数据集。数据集以场景理解为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置标定,含91个常见对象类别,其中82类有超过5 000个标签实例,共含32.8万幅图像和250万个标签实例。COCO Captions(Chen等,2015)在COCO图片数据的基础上由人工标注图片描述得到。
Conceptual Captions(Sharma等,2018)数据集:Conceptual Captions为从互联网获取的图文数据集。首先按格式、大小、内容和条件筛选图像和文本,根据文字内容能否较好地匹配图像内容过滤图文对,对文本中使用外部信息源的部分利用谷歌知识图谱进行转换处理,最后进行人工抽样检验和清理,获得最终数据集。Changpinyo等人(2021)基于Conceptual Captions将数据集的规模从330万增加到了1 200万,提出了Conceptual 12M。
HowTo100M(Miech等,2019)数据集:HowTo100M的内容为面向复杂任务的教学视频,其大多数叙述能够描述所观察到的视觉内容,并且把主要动词限制在与真实世界有互动的视觉任务上。字幕主要由ASR生成,以每一行字幕作为描述,并将其与该行对应的时间间隔中的视频剪辑配对。HowTo100M比此前的视频预训练数据集大几个数量级,包含视频总时长15年,平均时长6.5 min,平均一段视频产生110对剪辑—标题,其中剪辑平均时长4 s,标题平均长4个单词。
YT-Temporal-180M(Zellers等,2021)数据集:YT-Temporal-180M覆盖的视频类型丰富,包括来自 HowTo100M (Miech等,2019)的教学视频,来自VLOG(Fouhey等,2018)的日常生活记录短视频,以及Youtube上自动生成的热门话题推荐视频,如“科学”、“家装”等。对共计2 700万候选数据按如下条件删除视频:1)不含英文ASR文字描述内容;
2)时长超过20 min;
3)视觉上内容类别无法找到根据,如视频游戏评论等;
4)利用图像分类器检测视频缩略图剔除不太可能包含目标对象的视频。最后,还会应用序列到序列的模型为ASR生成的文本添加标点符号。
由于ASR生成的句子通常不完整,且没有标点符号,更重要的是不一定与图像内容完全对齐,所以Bain等人(2021)针对这一问题对抓取的网络视频进行人工标注,使得描述文本词汇丰富、格式良好且与视频视觉内容对齐,提出了WebVid-2M(Bain等,2021)数据集。
VQA(Antol等,2015),VQA v2.0(Goyal等,2019),GQA(Hudson和Manning,2019)数据集:一些研究(Tan和Bansal,2019;
Cho等,2021;
Zhang等,2021a)从VQA,VQA v2.0,GQA这类问答数据集获取预训练数据。使用时不包含测试数据,一般将问题描述与答案句子作为文本输入,与图像构成图文对,从而进行模态间的预训练。
1.2 预训练任务
表2列举了部分典型预训练任务,并在后文进行具体介绍。

表2 预训练任务举例Table 2 Examples of unsupervised pre-training tasks
掩蔽语言预测(mask language modeling, MLM)(Devlin等,2019):此任务最早由BERT引入,并在之后的预训练研究中广泛使用。在BERT中MLM是一个双向文本预测任务,对输入文本w中的每个单词进行随机屏蔽得到wm,让模型通过对上下文信息wwm的关联预测被遮盖的词语,D表示预训练数据集全集,w表示文本特征,v表示视觉特征,下标m表示掩蔽(mask)。在视觉语言多模态任务中(Li等,2019),使用文本对应的视觉特征v作为辅助线索,从而不仅驱动网络学习文本中单词间依赖关系,而且将视觉和语言内容对(w,v)对齐。损失函数为
LMLM=-E(w,v)~D(logP(wm|wwm,v))
(1)
式中,P()为概率函数。
掩蔽区域预测(mask region modeling, MRM):
MLM任务泛化到视觉模态,即选取视觉单元进行掩蔽,利用多模态信息预测该视觉单元。在图像中,选取区域特征(region feature)作为视觉单元,与以离散标签表示的文本标记不同,视觉特征是高维的、连续的,不同于文本分类任务有多种不同实现,具体实现方式如下两类所示。
掩蔽区域特征回归(mask region feature regression, MRFR)(Tan和Bansal,2019):对图像处理得到的感兴趣区域(region of interest, RoI)进行随机掩蔽,再将图像特征送入Transformer,对输出特征相应位置区域的特征向量后添加一个全连接层(fully connected layers, FC),得到变量f(vm)以将其投影到与原始RoI特征变量r(vm)相同的维度上,应用L2损失进行回归。损失函数计算为
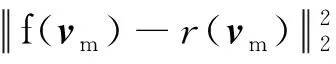
(2)
掩蔽区域类别预测(mask region classification, MRC)(Tan和Bansal,2019):MRC利用图像提取得到RoI特征及对应区域类别标签变量c(vm),对RoI特征进行随机屏蔽,将对应的最终输出特征经Softmax后得到变量s(vm),应用交叉熵(cross-entropy, CE)损失或相对熵(Kullback-Leibler divergence, KL)分类器进行对象分类,优化损失函数计算为
LMRCCE=E(w,v)~D(fCE(c(vm),s(vm)))
(3)
LMRCKL=E(w,v)~D(fKL(c(vm)|s(vm)))
(4)
掩蔽帧预测(mask frame modeling, MFM)(Luo等,2020):在视频中,一般与选取视频帧作为掩蔽预测的视觉单元。具体实现类似MLM与MRM可利用对比学习或应用L2损失进行回归(regression, R),损失函数计算为
LMFMCL=-E(w,v)~D(log P(vm|vvm,w))
(5)

(6)
视觉语言匹配(vision-language matching, VLM):任务的目标是对齐两个模态的信息,有助于在解决具体任务时利用模态间信息的交互,常引入对比学习构造正负例提升模型学习能力。具体实现方式如下两类所示。
图像—文本匹配(image-text matching, ITM)(Lu等,2019):构造图文关系对(w,v),标签y∈{0,1},负例通过将图文对中图像或文本替换为其他样本中随机选择的图像或文本来创建。将图文联合特征送入FC和Sigmoid函数构成的评分函数e(),判断文本是否为对应图片的描述表示,应用二元交叉熵损失进行优化,损失函数计算为

(7)
视频—文本匹配(video-text matching, VTM)(Sun等,2019b):与ITM类似,此任务先构造视频文本正例对集合(w,v)∈P和负例对集合(w,v)∈N,与ITM不同,除随机选择构造负例,还可使用同一视频其他片段,同一视频中的帧的相似性更高,可增强模型学习能力。然后对联合特征利用评分函数得到变量e(w,v)进行二值分类,但一般使用噪声估计(noise contrastive estimation, NCE)损失进行优化,损失函数计算为
P=E(w,v)~Pexp(e(w,v))
(8)
N=E(w,v)~Nexp(e(w,v))
(9)
(10)
除了以上使用较为普遍的预训练任务,部分工作针对模型需求设计新的任务。
文本—区域匹配(word region alignment, WRA)(Chen等,2020b):此任务通过最优传输(optimal transport, OT)(Chen等,2020a)最小化图像区域和句子中单词间的对齐成本,优化跨模态对齐,激励单词和图像区域间的细粒度匹配。
帧序预测(frame order modeling, FOM)(Li等,2020b):此任务的目的是学习利用视频的序列性,任务会随机打乱部分输入帧的顺序,然后将所有帧的最终编码特征送入FC再经Softmax后进行分类任务,预测每一帧对应的实际位置。
前缀语言预测(prefix language modeling, PrefixLM)(Wang等,2022):基于单向语言预测(unidirectional language modeling, LM)(Radford等,2018)任务引入零样本(zero-shot)能力的启发,对于输入的图文对,将图像视为文本描述的前缀。具体实施时,将图像特征序列置于文本序列之前,对前缀序列进行双向注意,对剩余序列进行单向注意。强制模型对前缀图像特征进行采样,来计算文本数据的LM损失。这一训练不仅能达到MLM学习双向上下文表示的目标,还能达到类似LM提升文本生成能力的目标。
掩蔽视觉令牌预测(masked visual-token modeling, MVM)(Fu等,2022):使用预训练好的离散VAE(variational autoencoders)(van den Oord等,2017),将视频帧“标记”为离散的视觉标记,预训练期时在空间和时间维度上屏蔽部分视频输入,让模型学习恢复这些被屏蔽的离散视觉标记。与MRM和MFM 相比有两个优势:一是MVM 在离散空间上进行预测,能避免特征维度过高的问题;
二是MVM 通过自监督训练获得潜在视觉标签,避免了使用特定视觉模块时提取视觉特征时存在的局限性。
除上述预训练任务之外,部分模型将视觉问答(Cho等,2021)、图像描述(image caption, IC)(Xia等,2021)等任务视为文本生成任务,直接利用多模态输入对答案进行文本预测,从而进行模型的预训练。
2.1 模型基础
2.1.1 基础结构
本文根据特征在进行视觉和语言模态融合处理之前是否进行处理,将VLP模型按结构分为单流式(single-stream)和双流式(cross-stream),如图1所示。

图1 单流结构和双流结构示意图Fig.1 Schematic diagram of single-stream structure and crosss-stream structure((a)single-stream structure; (b) cross-stream structure Ⅰ; (c) cross-stream structure Ⅱ; (d) cross-stream structure Ⅲ)
单流模型将视觉特征和语言特征直接输入融合模块,进行模型训练,其典型方式如图1(a)所示;
双流模型将视觉特征和语言特征分别进行处理,然后进行模态间的融合,典型类型包括但不限于图中3类:图1(b)中,模型首先对两路特征分别进行处理,然后进行跨模态融合;
图1(c)中,视觉特征经过视觉处理模块后,与文本特征一同送入多模态融合模块进行交互;
图1(d)中,两路特征送入各自处理模块后进行交互式的参数训练。
2.1.2 基础方法
对于视觉输入特征,在处理2维图像或处理帧级别的视频时常采用Faster RCNN(region convolutional neural network)(Ren等,2015)、ResNet(residual neural network)(He等,2016)等模型,3维视频片段常使用S3D(separable 3D CNN)(Xie等,2018)和Slow-Fast(Feichtenhofer等,2019)等处理。ViT(Dosovitskiy等,2021)方法因处理方式简易且效果较好,所以在2维和3维视觉处理中均有使用。对于语言输入的处理通常采用BERT或类似的多层双向Transformer编码器。
多模态融合常采用Transformer结构,如图2所示,其由多层编码器—解码器(encoder-decoder)结构组成,N为层数,编码器中含有两个多头注意力机制模块(multi-head attention, MHA),其由多个自注意力层组成。编解码器均通过残差连接相加并进行正则化,并通过前馈神经网络层(feed forward layer)进行激活。

图2 Transformer结构示意图Fig.2 An illustration of the Transformer structure
Transformer的核心是位于MHA之中的自注意力层(self-attention layer)。自注意力层的输入来自添加位置编码(position encodin)的文本或视觉特征词向量F={f0,f1,…,fn},将输入线性转换为3个不同向量:查询(query):Q∈Rn×dQ、键(key):K∈Rn×dK和值(value):V∈Rn×dV,自注意操作Att()通过式(11)来学习词与词间的关系
将多个自注意力层的输出进行拼接,然后通过线性层输出即为MHA的输出,其与输入特征的维度相同。在解码器的第2个MHA中,键和值来自本层编码器,查询来自上层解码器。MHA的输出结合上下文信息,再通过一个前馈网络经过非线性变化,输出综合了上下文特征的各个词的向量表示。
2.2 图像—文本多模态预训练模型
该类模型信息如表3。
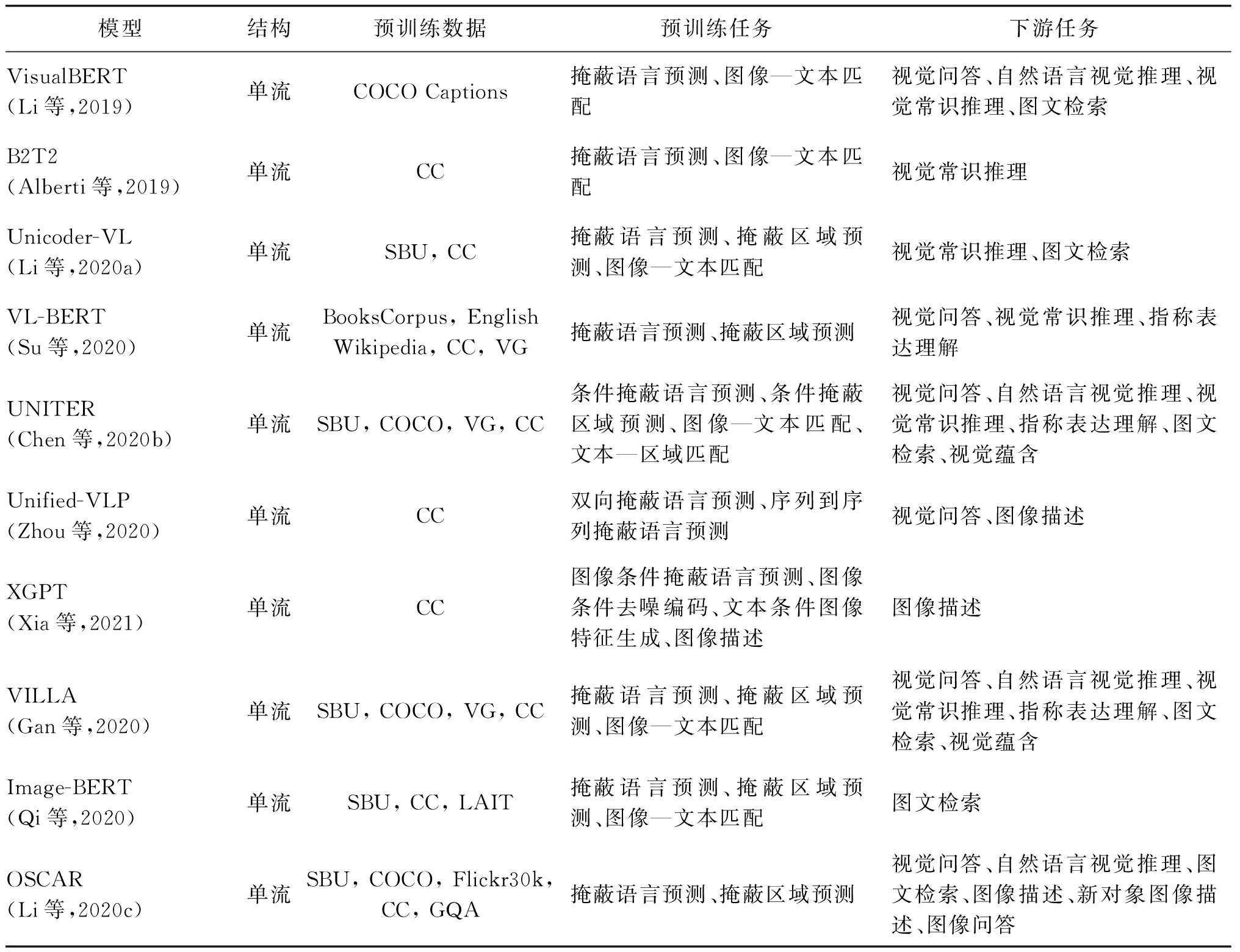
表3 图像—文本多模态预训练模型信息Table 3 Information summary of image-text multimodal pre-training models
2.2.1 单流模型
单流模型相对双流模型结构较简单,一般将图像与文本两种模态信息置于等同重要位置,对图像和文本编码后共同输入跨模态融合模块进行预训练。对于输入图像是否采用目标检测算法,可对研究进行更细致的分类。
1)采用目标检测算法。Li等人(2019)提出的VisualBERT为较早进行图像—文本预训练的工作,模型结构如图3所示。对于文本输入,采用类似BERT的方式进行处理,首先将文本分割成一个单词序列,然后使用WordPiece(Wu等,2016)对每个单词进行标记,最后采用一个编码矩阵处理得到原词编码(token embedding)序列,其中添加[CLS]作为文本开端,[SEP]作为图文分隔。将原词编码、区分输入不同模态的片段编码(segment embedding)和序列位置编码(sequence position embedding)映射到同一维度组合成文本的最终编码。对于图像输入,采用目标检测算法,如Faster-RCNN提取区域特征编码,与片段编码和位置编码组合映射到文本编码相同维度得到最终编码。对于序列位置编码,语言部分一般采取升序来表示文本描述中词的顺序,对于视觉部分,当输入提供单词与边界区域间的匹配时,会设置为匹配单词对应的位置编码的总和。将文本和图像最终编码共同输入Transformer进行MLM和ITM预训练,应用于4类下游图像文本任务。VisualBERT证明了类BERT结构应用于无监督图像—文本预训练的有效性。

图3 VisualBERT结构示意图(Li等,2019)Fig.3 An illustration of the VisualBERT structure (Li et al., 2019)
VisualBERT对文本输入采用类BERT文本编码形式和对图像输入使用目标检测算法的图像编码形式在后续研究中广泛使用。
Li等人(2020a)提出的Unicoder-VL(universal encoder for vision and language)对图像输入使用Fas-ter-RCNN提取RoI视觉特征时、还生成区域对象标签及区域空间位置特征。区域对象标签用于MRC训练,空间位置特征含RoI边界框(bounding box)4个顶点的值坐标(归一化在0和1之间)和区域面积(相对面积,区域面积与图像面积之比,指在0和1之间)。将RoI视觉特征和空间位置特征通过FC投影到同一维度空间,二者相加后送入归一化层(layer normalization, LN)得到最终视觉编码,与文本编码一起送入Transformer进行MLM、MRC和ITM训练。Su等人(2020)提出的VL-BERT(visual-language BERT)在进行图像编码时,新增了一个视觉特征编码(visual feature embedding),具体为非视觉输入部分对应整个图像提取的特征,视觉输入部分对应图像经特征提取器所提取的特征,同时在词编码上增加一个特殊符[IMG]对应RoI图像标记。具体结构如图4所示。
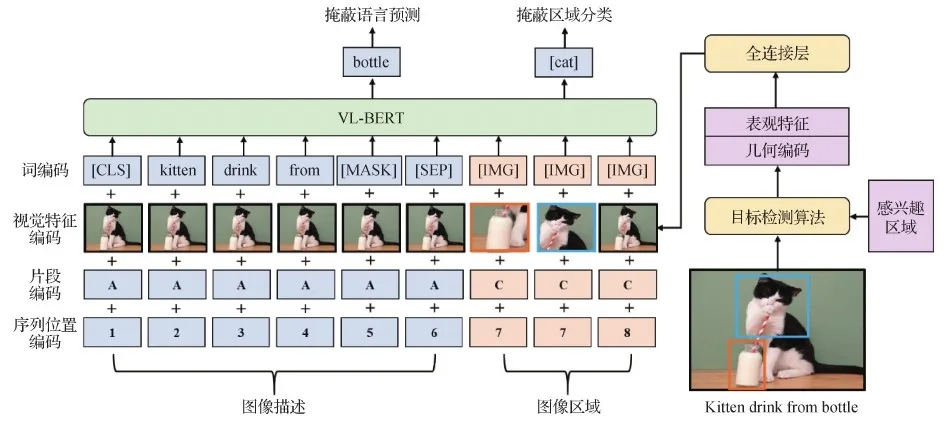
图4 VL-BERT结构示意图(Su等,2020)Fig.4 An illustration of the VL-BERT structure(Su et al., 2020)
Li等人(2020c)首次引入目标检测中的区域分类标签作为视觉和语言层面上的锚点(anchor point),使图文间的语义对齐任务得以简化,提出了Oscar(object-semantics aligned pre-training),模型结构如图5所示,利用特征提取器给每个区域输出的分类标签,将输入图文对表示为单词序列w、分类标签q、区域特征v三元组,令w、q和v共享相同的语义特征,从而将预训练优化目标变为最小化视觉损失和文本损失之和。输入三元组可以从两个角度理解,即模态视角和字典视角。因标签序列由特征抽取模型分类得到,所以模态为图像,表示形式为文本,使用文本的字典。分类标签实现了输入层面上的跨模态。考虑到视觉特征对于VLP模型的重要性,团队进一步研究对Oscar的物体检测模型(object detecter, OD)进行了改进,提出了 VinVL(Zhang等,2021a),表明更好的视觉特征可有效改善视觉语言模型的表现。
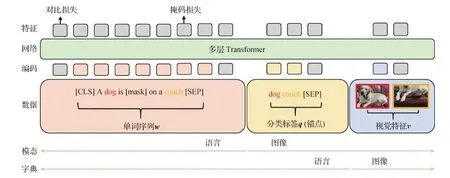
图5 Oscar结构示意图(Li等,2020c)Fig.5 An illustration of the Oscar structure(Li et al., 2020c)
除对输入的编码处理进行改进,一些研究通过改进预训练任务来增强模型的学习能力。Chen等人(2020b)提出的UNITER(universal image-text representation)采用条件掩蔽MLM和MRM预训练任务,有别于传统设定的双模态随机掩蔽,掩蔽一种模态时保持另一模态不变,这可防止区域与对应描述单词同时被掩蔽造成不对齐问题。此外,设计了文本—区域匹配预训练任务,通过最优传输最小化图像区域和句子中单词间的对齐成本,优化跨模态对齐,激励单词和图像区域间的细粒度匹配。
Zhou等人(2020)提出的Unified-VLP(unified vision-language pre-training),在传统MLM任务上新增双向(bidirectional)和序列到序列(sequence-to-sequence)目标以增强编码器和解码器间的联系。
Xia等人(2021)提出的XGPT(cross-modal generative pre-training)为提升模型在下游生成任务上的表现,除引入图像描述任务外还设计了3个新的预训练任务:图像条件掩蔽语言预测(image-conditioned masked language modeling, IMLM)、图像条件降噪自编码(image-conditioned denoising autoencoding, IDA)和文本条件图像特征生成(text-conditioned image feature generation, TIFG)。
在预训练过程中,采用有效的预训练策略也有助于提升模型能力。Qi等人(2020)提出的ImageBERT工作中从互联网搜集了一个大规模视觉和文本信息的数据集(large-scale weak-supervised image-text, LAIT),基于此设计了多阶段预训练策略,即先在规模最大但质量较低的LAIT上训练,然后在高质量CC和SBU上训练。实验结果表明预训练中不同质量数据集的使用顺序对性能有很大的影响。
Li等人(2021b)采用多模态对比学习(cross-modal contrastive learning, CMCL),利用丰富的非成对单模态(non-paired single-modal)数据,让文本和视觉知识在统一的语义空间中相互增强,提出UNIMO(unified-modal)能同时有效处理单模态和多模态任务。
Gan等人(2020)在预训练和微调过程中对图像和文本编码特征增加扰动以增强模型的泛化性,提出了VILLA(vision-and-language large-scale adversarial)。Hu等人(2021)指出可以利用数据集中数量远远大于图像—描述对的图像—标签对信息来学习视觉词汇,提出了VIVO(visual vocabulary)模型。Cho等人(2021)对文本编码添加代表不同任务的前缀编码,以一个统一的文本生成目标来处理各视觉语言任务。
2)不采用目标检测算法。以上方法均使用目标检测算法进行图像处理,一些工作无需使用目标检测算法或针对其不足进行研究。
下游视觉常识推理任务(visual commonsense reasoning, VCR)所使用的数据集含区域边框信息,所以Alberti等人(2019)针对性地设计了B2T2(bounding boxes in text transformer)在对VCR进行微调时,将图像区域特征和区域边界框等视觉信息直接插入文本编码序列中得到多模态“句子”作为输入进行预训练,在VCR任务中与双流式结构进行对比,表明早期融合图文信息的单流式结构具有更好性能。
Huang等人(2020b)认为,目标检测算法所能提供的RoI类别限制了特征表示能力,会丢失场景和情感等更广泛语义的视觉信息。此外,RoI区域为矩形,会包含有噪声的背景,丢失形状和空间关系信息。为充分利用原始图像的视觉信息,提出了Pixel-BERT,学习用像素来表示图像,对于输入图像,使用ResNet对图片进行卷积、池化,最后得到一个特征矩阵,元素为特征向量,对其进行采样后,每个元素与一文本编码相加,作为一种偏置,最后展平,得到最终的像素特征编码输入Transformer进行训练。
受到ViT工作的启发,Kim等人(2021)将输入图像切块成一个图像patch序列,通过线性投影而非卷积操作转化成特征编码,然后和位置编码进行相加,最后和文本编码进行集合得到最终编码输入Transformer,提出结构简单的模型ViLT(vision-and-language transformer)。相比基于图像区域特征的方法处理速度大幅度提升。Wang等人(2022)采用类似的视觉处理方式,利用大规模弱标记数据集(Jia等,2021)只采用一个前缀语言预测预训练任务进行端到端训练,提出了一个极简的模型SimVLM(simple visual language model),在多个下游任务中表现优秀,具有强大的泛化和迁移能力。
Dou等人(2022)从多个维度研究模型设计对模型性能的影响,对比研究原始ViT及其拓展的多个视觉编码方法(Bao等,2021;
Liu等,2021b;
Radford等,2021;
Touvron等,2021a,b;
Yuan等,2021)、原始BERT及其拓展的多个文本编码方法(Liu 等,2019b;
Clark 等,2020;
Lan 等,2020;
He等,2021b)、不同多模态融合模块(合并注意力与协同注意力)、不同架构设计(仅编码器与编码器—解码器)以及预训练目标(MLM, ITM等)对模型性能的影响,综合提出了METER(multimodal end-to-end transformer)模型,研究得出在VLP中ViT比文本编码器更重要的结论,以及其他一些VLP模型设计的结论。
针对目前中文图像文本多模态模型缺失的情况,Lin等人(2021)提出了1 000亿参数的大规模中文多模态预训练模型M6(multi-modality to multi-modality multitask mega-Transformer),构建了一个超大规模中文多模态预训练数据集M6-Corpus。Lin等人(2021)对1百万幅电子商务领域图像数据抽样进行对象检测后发现90%图像所含物体少于5类,且高度重叠,因此,对图像进行切块并利用ResNet提取特征,将各patch特征按位置线性组合成表示序列,与文本特征组合后送入Transformer进行文本—文本传输(text-to-text transfer)、图像—文本传输(image-to-text transfer)、多模态—文本传输(multimodality-to-text transfer)预训练任务。M6使用大规模分布式方法进行训练,大幅度提升了模型的训练速度,适用于广泛任务。
2.2.2 双流模型
由于图像和文本信息在属性上区别较大,将不同模态输入置于相同输入地位可能对模态间匹配造成不良影响。在这一假设下,部分模型根据多模态输入特点设计双流预训练模型,使用不同编码器灵活处理各自模态特征,并通过后期融合对不同模态进行关联。
Lu等人(2019)认为对语言信息需采取较深网络才能获取抽象知识,而图像经Faster-RCNN处理已经过较深网络,无需再次经历更深编码过程,于是提出典型双流式结构模型ViLBERT(vision and language BERT),模型结构如图6所示,上下两路分别独立处理视觉和文本输入,视觉输入采用Faster-RCNN处理,文本输入采用类BERT处理,在编码之后经协同注意(co-attention)Transformer进行特征跨模态融合,然后进行MLM和ITM训练。ViLBERT的核心为跨模态融合模块co-attention Transformer结构,如图7所示,对于视觉和语言输入,将各自的键K和值V输入另一模态,而对查询Q输入自身模态,使得图像区域作为上下文信息给文本信息进行加权,反之亦然。

图6 ViL-BERT结构示意图(Lu等,2019)Fig.6 An illustration of the ViL-BERT structure(Lu et al., 2019)

图7 协同注意力Transformer层 (Lu等,2019)Fig.7 Co-attention Transformer layer (Lu et al., 2019)
在进一步研究中,对ViLBERT预训练过程中视觉信息泄漏和负样本噪声问题进行优化,并将单个模型用于12个视觉语言任务提出了12-in-1(Lu等,2020)。研究提出多任务学习预训练方法,训练时融入动态训练调度器(dynamic stop-and-go training scheduler)、基于任务的输入标记(task dependent input tokens)和简单启发式超参(simple hyper-parameter heuristics)。实验结果表明多任务学习是一种有效的预训练任务,可避免因数据集规模造成的训练过度或训练不足的问题。
ViLBERT对图像和文本的双流式处理在后续研究中广泛使用。Tan和Bansal(2019)认为视觉概念和语言语义间的关系对推理问题很重要,所以在图像编码时引入对象关系编码器,提出了LXMERT(learning cross-modality encoder representations from transformers)。Yu等人(2021)在文本编码时,将语言转化为结构化的场景图,使模型能更精准把握图文间细粒度的对齐信息,提出了知识增强型模型ERNIE-ViL(knowledge enhanced vision-language representations),设计了场景图预测(scene graph prediction, SGP)预训练任务,含对象、属性和关系预测,通过对场景图中图像和文本信息进行掩蔽,以预测场景图中的节点属性和关系,学习细粒度的跨模态语义对齐信息。Li等人(2021c)使用独立的解耦编码器和解码器分别处理不同VLP任务,利用不同模式VLP任务间相关性来增强下游任务的鲁棒性,提出模型TDEN(two-stream decoupled encoder-decoder network)。
COCO等高质量预训练数据集收集后需进行烦杂的清理过程,针对这一点,Jia等人(2021)搜集了一个18亿数据量的含噪数据集,并提出了ALIGN(a large-scale image and noisy-text)方法,使用对比损失对齐图文对的视觉和语言表示。方法在大量下游任务上表现优秀,表明语料库的规模可弥补其噪音,提升模型性能。同一时期,Radford等人(2021)利用互联网上大规模的图片信息构建了一个4亿大小的图文对数据集,将自然语言作为监督以提升图像分类效果,使用对比学习方法促进图像和文本的匹配能力,提出了CLIP(contrastive language-image pre-training)。对于视觉编码分别尝试了 ResNet和ViT,根据具体任务表现进行取舍。模型在27个下游任务数据集上表现卓越,表明了与有标签监督学习对比有着较强的泛化能力。
大部分图文预训练模型都假设图像与文本模态间存在强相关关系,Huo等人(2021)认为这种假设在现实场景中难以存在,因此基于图文对弱相关假设选择隐式建模,提出大型图像—文本预训练模型BriVL(bridging vision and language)。方法使用多模态对比学习框架进行训练,构建队列字典以增加负样本数量。此外还提出一个大型中文多源图像文本数据集RUC-CAS-WenLan,含3 000万图文对。实验表明在参数量足够大时双流模型较单流模型具有一定优势。
2.2.3 其他模型或方法
预训练数据集与下游数据集存在域偏移,而现有方法是纯概率角度出发的,这会导致一定程度的虚假关联。Zhang等人(2020a)提出一个基于因果的去混淆模型DeVLBert(deconfounded visio-linguistic Bert),将后门调整方法融入预训练模型。实验证明,DeVLBert作为整体模型的灵活部分组件,对广泛的单流、双流预训模型具有很好的适用性。预训练任务和下游任务的训练模式也相差较大,针对这一问题,Yao等人(2022)提出颜色提示优化模型CPT(colorful prompt tuning),利用颜色促进方法作为两种训练模式之间的桥梁,缩小预训练任务与下游任务之间的差异性。模型结构如图8所示,方法在视觉检测过程中对视觉目标区域添加不同颜色,并通过颜色信息作为图像和文本的共同标记信息,通过对颜色信息进行MLM任务,将图文关联转换为完形填空问题,加强了图文联系,从而对下游的图像目标定位问题起到了促进作用。

图8 CPT结构示意图(Yao等,2022)Fig.8 An illustration of the CPT structure(Yao et al., 2022)
生活中存在大量文档图像处理任务,如表格理解、文档图像分类、收据理解和表单理解。为此,Xu等人(2020)提出LayoutLM(pre-training of text and layout),重视文档图像的布局和样式信息理解,对扫描的文档利用光学字符识别(optical character recognition, OCR)处理,将识别得到的文字片段和对照的图像进行联合建模,首次将文本和布局结合在一个框架中进行文档级预训练,使用了MLM和多标签文档分类预训练任务。在进一步研究中,引入ITM任务,并在传统自注意力机制基础上显式添加空间相对位置信息,帮助模型在1维文本序列基础上加深对2维版面信息的理解,提出了LayoutLMv2(Xu等,2021b)。
在加入音频的图文预训练方面,Liu等人(2021a)提出了大规模图文音三模态模型OPT(omni-perception pre-trainer),使用3种预训练任务:1)token级别建模,即对于3种单模态信息分别进行掩码和预测;
2)模态级别建模,即将某一到两个模态的信息进行整体掩码并重建;
3)样本级别建模,即将3个模态的样本对中的某一到两种进行替换,使得模型对于模态类别是否匹配进行预测。对于下游任务,该方法可以同时适应单流、双流和三流的输入,同时具备进行理解式任务与生成式任务的能力。
2.3 视频—文本多模态预训练模型
该类模型总结如表4。
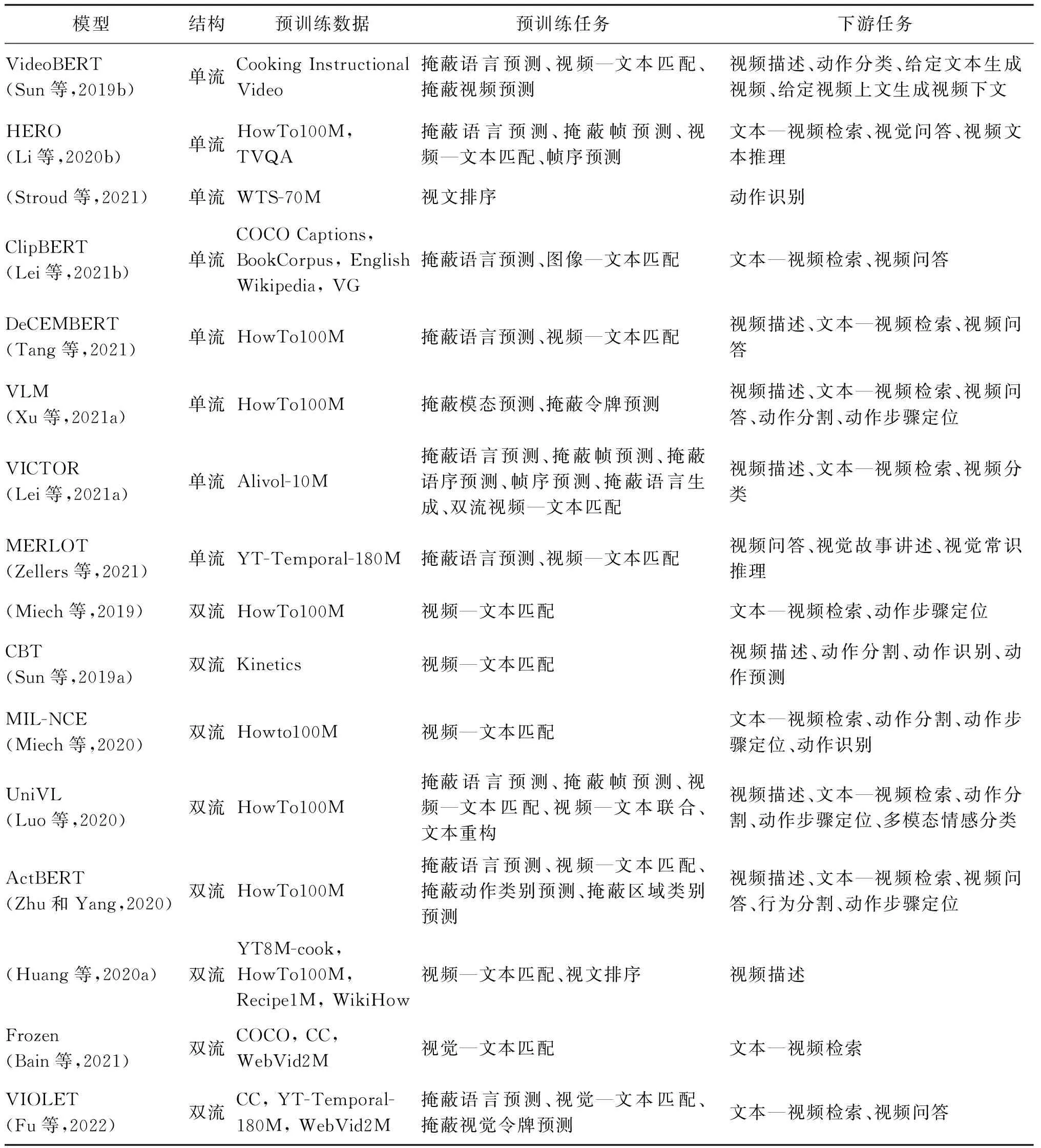
表4 视频—文本多模态预训练模型信息Table 4 Information of video-text multimodal pre-training models
2.3.1 单流模型
Sun等人(2019b)提出的VideoBERT模型是第1个将Transformer结构拓展到视频语言预训练的工作,模型结构如图9所示。对ASR得到的文本输入采取常用的类BERT处理,对于视频输入,按20帧/s的采样速度从视频剪切多个1.5 s视频片段,应用预训练过的S3D提取视频特征,然后采用层级k聚类(hierachicalk-means)标记视觉特征,以聚类中心对视频特征进行矢量量化(vector quantization, VQ)操作。文本与视频的联合特征被送入多模态Transformer进行MLM,VTM和掩蔽视频预测(video only mask completion, VOM)预训练任务。VOM以聚类的视频片段作为被掩蔽和预测的视觉单元。模型目标是学习长时间高级视听语义特征,如随时间推移而展开的事件与动作,采用网络收集的厨艺教学视频作为预训练数据,在预设下游任务上表现良好,但由于视觉中心代表的视觉信息难以全面描述视频内容,使得模型的泛化性受到一定限制。
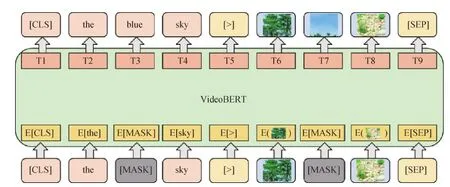
图9 VideoBERT 结构示意图(Sun等,2019b)Fig.9 An illustration of the VideoBERT structure(Sun et al., 2019b)
VideoBERT对视频帧进行聚类的离散化表示会丢失视频细粒度信息,在后续的研究中较少采用。
Li等人(2020b)提出的HERO(hierarchical encoder for video+language omni-representation)中,对视频输入切分成片段并提取视频帧后,使用ResNet和Slow-Fast为每个视频帧提取2维和3维视觉特征,再通过FC以投影到与文本编码同一维度特征空间中。由于视频帧是连续的,它们的位置编码可以同文本编码一样处理,帧的最终编码是通过将FC输出和位置编码相加,然后通过 LN 层获得的。HERO采用分层式结构而非类BERT的扁平式编码器对多模态输入进行编码。引入了一个时序Transformer,将每一视频帧前后的所有帧作为全局上下文,并基于此设置了帧序预测预训练任务,即随机打乱部分输入帧的顺序,然后预测每一帧对应的实际位置,从而学习利用视频的序列性。消融实验证明FOM对依赖时序推理的问答任务提升较大。数据集的使用上,在常用的叙述性教学视频基础上引入动态场景和复杂社会互动的影视视频。
对整个视频进行密集采样视频帧以提取视觉特征,所需计算量较大。为克服这一缺点,Lei等人(2021b)提出ClipBERT,假设视频中少量图像即可反映整体视频信息,因为连续的视频片段通常包含来自连续场景的相似语义。在每一个训练步骤中只从完整的视频中稀疏地采样一个或几个短的片段进行训练。同时,利用图像—文本预训练模型进行参数初始化,使用在视频理解任务中被证明有效的2维结构ResNet代替传统3维结构,如I3D(Carreira和Zisserman,2017)作为视频编码的视觉主干。ClipBERT所采取的策略能有效减缓端到端训练的学习负载,降低内存开销和运行时间,在下游检索和问答任务6个数据集的实验结果也证明了策略的有效性。
视频预训练数据集中的字幕文本一般通过ASR生成,所以可能存在描述信息无法包括所有内容以及描述词汇与图像内容不对齐问题,这会影响预训练模型的学习效果。Tang等人(2021)针对这一问题提出了DeCEMBERT模型(dense captions and entropy minimization)。在预训练过程中,利用稠密描述(dense captions)方法处理视频得到额外的视频描述文本以包括更多的图像内容。引入基于熵最小化约束注意力损失(entropy minimization-based constrained attention loss)激励模型从字幕候选池中选择与图像内容匹配最佳的描述。模型在3类下游任务上表现良好。
由于能作为视频预训练使用的数据集较少,一些研究提出了各类视频数据集和基础方法(baseline model)。
Lei等人(2021a)提出一个大规模、高质量的中文视频语言数据集Alivol-10M和基础方法VICTOR(video-language under-standing via contrastive multimodal pre-training)。Stroud等人(2021)收集了7 000万互联网视频形成多模态数据集WTS-70M,相较HowTo100M,视频类型更多样。作者使用3D卷积对视频输入进行特征提取,并使用BERT对视频所对应的元文本数据进行编码,然后通过计算视频与元数据的排序损失进行训练。所提方法在下游动作识别(action recognition)任务上表现良好。
Zellers等人(2021)公开了视频类型丰富的大规模数据集YT-Temporal-180M,并基于对人类跨时间执行多模态推理这一能力的认识,训练了具有时间常识学习能力的模型MERLOT(multimodal event representation learning over time),模型不仅可以学习将图像与时间对应的单词进行匹配,还可以推理随时间变化的全局范围内的上下文事件,在12个不同的视频问答数据集中表现优秀。
2.3.2 双流模型
Miech等人(2019)提出了视频文本预训练中得到广泛使用的大规模叙述性视频数据集HowTo100M,baseline方法将提取到的视频和文本特征映射到相同维度从而优化模态间的关联性。Miech等人(2020)进一步研究发现HowTo100M中由于人的讲述与画面展示不同步,导致大约50%的视频剪辑片段与ASR描述文本没有对齐(如图10所示)。为解决这一偏差问题引入了多实例学习(multiple instance learning, MIL),基于同一视频中连续时间内画面语义相似的前提,在目标视频片段的相邻时间内截取多个视频—描述对作为对比学习的候选正例。然后采用噪声估计NCE来优化视频文本联合特征的学习,提出了MIL-NCE,在8个数据集4类下游任务中表现良好。MIL-NCE方法在后续使用HowTo100M数据集的预训练模型中广泛使用。

图10 叙事性视频中的信息失调(Miech等,2020)Fig.10 Misalignments in narrated videos(Miech et al., 2020)
VideoBERT中聚类的视觉表示会丢失细粒度视觉信息(如更小的物体和微妙的运动),因此Sun等人(2019a)进一步研究提出了双流式结构模型,将ASR得到的文本输入采用BERT进行处理,对于视频输入,舍弃此前对视频帧进行矢量量化的操作,将视频分段提取的视频帧经S3D提取后的特征送入设计的对比学习模块CBT(contastive bidirectional transformer),得到最终视频特征,最后连同经BERT提取的文本特征一起送入跨模态Transformer,将多模态序列结合,计算模态间的相似度得分,并利用噪声估计学习视频句子对之间的关系。方法主要用于单独的视频表示学习,文本输入仅被视为辅助信息,在4类下游任务,尤其与动作特征相关的任务上表现优秀。
Luo等人(2020)针对下游生成式任务提出了UniVL(unified video and language pre-training),引入了生成式预训练任务文本重构(language reconstruction, LR),即采用一个自回归解码器,其输入为处理后的文本和视频帧,输出是原始文本。还设计了两种预训练策略:1)逐阶段预训练。先对双模态输入利用NCE训练,再以较小的学习率对整个模型进行所有目标的训练。2)增强视频表示。以15%的可能性屏蔽整个文本输入,使模型利用视频信息生成文本。模型在5类下游任务上表现良好。Huang等人(2020a)则引入文本预训练中的掩码序列到序列(masked sequence to sequence, MASS)预训练方法(Song等,2019),以提升模型在视频描述任务上的表现。
Zhu和Yang(2020)提出了全局局部动作VLP模型ActBERT,结构如图11所示,对于视频输入采取两种编码处理。首先是动作编码,加入全局堆叠帧获取全局动作信息,动作信息来自每个视频相应描述中提取动词所构建的字典,为简化问题删除了没有任何动词的视频片段。然后是视觉编码,加入经Faster-RCNN对图像提取的RoI特征获取局部区域信息。ActBERT利用全局动作信息来促进文本与局部目标区域间的交互,使一个视觉中心能同时描述局部和全局视觉内容,提升视频和文本的关联性。引入了掩蔽动作分类(mask action classification, MAC),即随机掩蔽输入的动作表示向量,使模型通过其他信息如文本信息和物体信息来预测出动作标签。模型在5类下游任务上表现良好。

图11 ActBERT结构示意图(Zhu和Yang,2020)Fig.11 An illustration of the ActBERT structure(Zhu and Yang, 2020)
Bain等人(2021)认为图文检索与视频—文本检索任务有许多信息是重叠的,提出了模型Frozen,将图像与视频一起训练以提升预训练效果。模型对图像和视频片段采用ViT方法提取patch后,经线性投影相加,与时空位置编码一起送入Transformer编码器,而后输出视觉特征,对描述采用类BERT处理得到文本特征,将二者线性投影到同一空间内执行点积操作计算相似度。方法提升了检索速度,在多个下游检索任务中表现优秀。针对视频数据集ASR生成描述文本的不足,作者还公开了一个人工标注描述的大规模视频数据集WebVid-2M。
为了更好地学习视频表示,Fu等人(2022)针对此前MRM与MFM任务的局限性设计了一个新的预训练任务MVM,利用swim Transformer(Liu等,2021b)处理图像与视频输入,提出了一个端到端的模型VIOLET(vIdeo-language transformer),在下游问答与检索任务上表现优秀,实验结果也证明MVM增强了模型对视频场景理解的有效性。
2.3.3 其他模型或方法
预训练数据集与下游任务数据集间存在源—目标领域差距,针对这一问题,Zhou等人(2021)提出CUPID(curation of pre-training data),通过领域聚焦的预训练方法减小数据集之间的差距。实验表明,与随机抽样和利用完整预训练数据集相比,对较小的领域聚焦数据子集进行预训练可有效地缩小源—目标领域差距,获得性能增益。
多模态数据中普遍存在噪声,Amrani等人(2021)证明了噪声的存在会导致预训练模型得出次优结果,并认为多模态数据的噪声估计问题可简化为多模态密度估计任务。基于这一点,提出了一种严格基于不同模态间内在相关性的多模态表示学习噪声估计方法。在2类任务中证明了将该方法集成到多模态学习模型中可提升实验效果。为支持实证结果和分析失效情况,作者还提供了一个理论概率误差界。
视频数据通常含有音频信息,因此,部分研究利用音频内容增强模型的表征学习能力。
Gabeur等人(2020)提出了MMT(multi-modal transformer)模型,将多种模态信息纳入预训练过程用以提升视频检索任务,输入类型具体包括运行特征、场景特征、面部特征、表观信息、音频特征、OCR字幕信息和转化为文本的语音信息,MMT将聚合得到的视频多模态特征与文本特征映射到相同维度的特征空间中,并进行跨模态联合编码,最终模型在视频检索数据集上取得了较好结果。
Akbari等人(2021)提出VATT(video-audio-text transformer),将视频、语音和文本3个模态的信息通过线性投影映射为特征向量,利用单个Transformer对3种模态的信息进行统一编码,然后构造负样本的视频—文本对和视频—语音对,以进行多模态对比学习。
3.1 图像—文本多模态预训练模型
图像—文本多模态下游任务繁多,代表性的任务有:1)分类任务,如视觉问答(Johnson等,2017;
Hudson和Manning,2019)、自然语言视觉推理(natural language visual reasoning, NLVR)(Suhr等,2017,2019)、视觉常识推理(Gao等,2019)、指称表达理解(referring expression comprehension, REC)(Yu等,2016b;
Mao等,2016)和视觉蕴含(visual entailment, VE)(Xie等,2019a,b)等;
2)检索任务,如图文检索(image-text retrieval)(Karpathy和Li,2015;
Plummer等,2015;
Lee等,2018);
3)生成任务,如图像描述(Vinyals等,2015;
Xu等,2015;
Anderson等,2018)、新对象图像描述(novel object captioning, NoCaps)(Agrawal等,2019)及多模态翻译(multimodal translation)(Elliott等,2016)。以下对表5中VLP模型所进行对比的下游任务与相关数据集进一步介绍。

表5 图像—文本预训练模型部分下游任务性能对比Table 5 Comparison of some downstream task results of image-text pre-training models /%
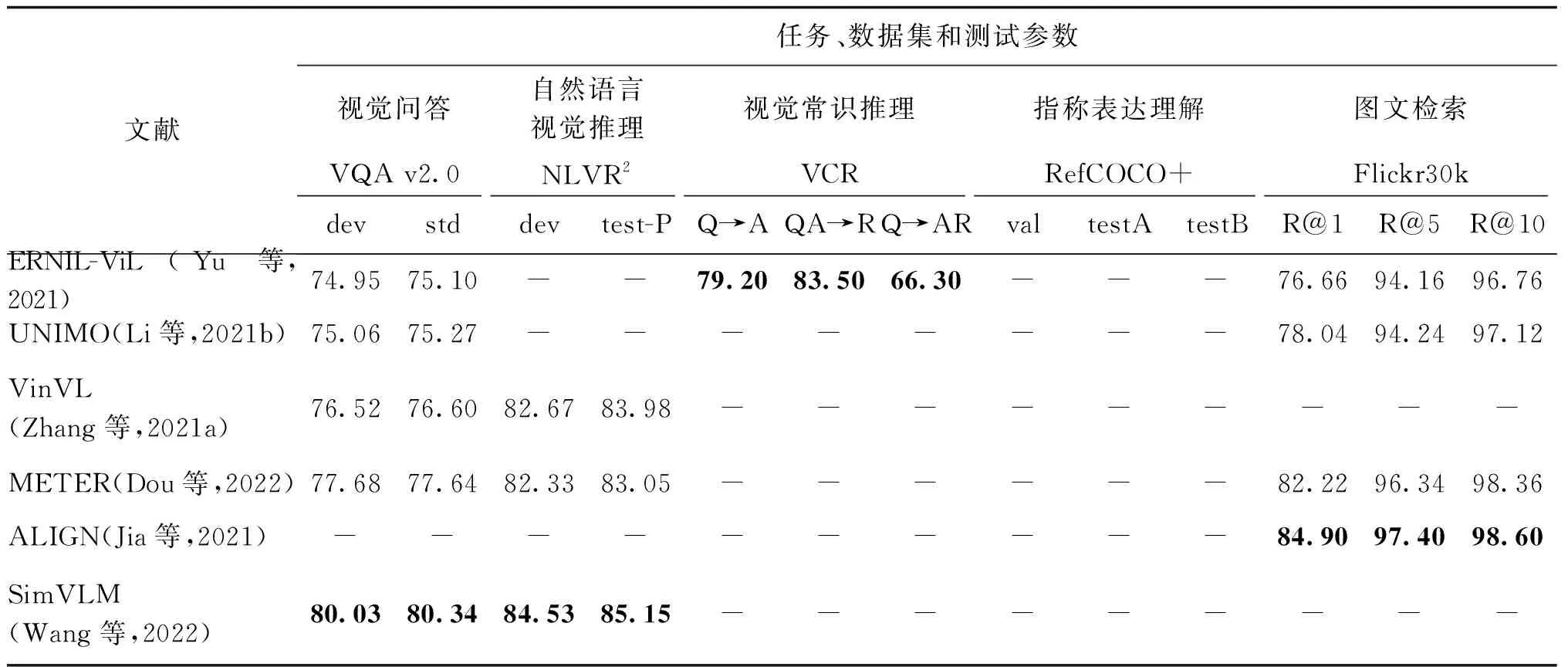
续表5 图像—文本预训练模型部分下游任务性能对比Table 5 Comparison of some downstream task results of image-text pre-training models /%
视觉问答:通过给定图像,回答关于图像内容的相关问题,题目类型包括选择题和判断题,问题一般为对图像中的对象进行分类、识别以及关系推断等。本文所示为VQA v2.0(Goyal等,2019)数据集中两个测试子集test-dev(dev), test-standard(std),结果为准确率。
自然语言视觉推理:给定一对照片和对它们的描述,判断描述是否正确,需对输入进行集合、计数、比较和空间关系的推理。使用NLVR2(Suhr等,2019)数据集,结果对比为development(dev)和test-P两个测试子集上的准确率。
视觉常识推理:任务包含两个阶段。第1阶段为问题回答,通过给定图片、问题和多个答案选项,选择正确答案;
第2阶段为论证,对给出回答的原因再进行一次多项选择。使用VCR(Zellers等,2019a)数据集,模型在此任务上需学习到更高层次的认知和常识推理。结果对比为测试集回答(Q→A)和论证(QA→R)两个子阶段及整体回答(Q→AR)的准确率。
指称表达理解:通过给定图像和对其中某一区域的描述,利用描述定位该区域。对比数据为RefCOCO+(Kazemzadeh等,2014)数据集中验证集(val)和两个测试集(testA,testB),使用检测区域(detected regions),结果为准确率。
图文检索:该任务包含两类子任务,1)文本—图像检索(text-to-image retrieval, IR),给定图像描述和候选图像库,利用给定描述检索出正确图像;
2)图像—文本检索(image-to-text retrieval, TR),给定图像和候选描述文本库,利用给定图像检索出正确描述。对比使用数据集Flickr30k(Young等,2014)上的测试集,指标R@1/5/10为正确答案位于前1、5、10顺序的召回率。
3.2 视频—文本多模态预训练模型
关于视频的视觉—语言交叉任务同样覆盖广泛,代表性的任务有视频描述(Gan等,2017;
Krishna等,2017a)、文本—视频检索(Gao等,2017;
Hendricks等,2017;
Mithun等,2018;
Lei等,2020b)、视频问答(video question answering)(Yu等,2018;
Lei等,2020a)、动作分割(action segmentation)(Tang等,2019)、步骤定位(action step localization)(Zhukov等,2019)、动作识别(Kuehne等,2011;
Soomro等,2012)、视频摘要(video summarization)(Plummer等,2017)和视觉故事讲述(visual storytelling)(Agrawal等,2016;
Huang等,2016)。以下对表6中VLP模型所进行对比的下游任务与相关数据集进行进一步介绍。

表6 视频—文本预训练模型部分下游任务性能对比Table 6 Comparison of some downstream task results of video-text pre-training models
视频描述:通过给定一段视频,生成对视频内容的描述。任务使用Youcook2(Zhou等,2018a)数据集中验证集,其中每个视频片段都对应有一个标注句子。结果所使用的4个指标如下:1)BLEU-4(B-4),表示视频描述与标注4-gram重合度;
2)METEOR(M),表示视频描述所使用的词汇与标注词汇的同义词表相似度;
3)ROUGE-L(R),表示视频描述所具备的总结能力,为召回率指标;
4)CIDEr(C),表示视频描述与图像相关性度量。
文本—视频检索:通过给定查询文本,从视频库中检索相关视频片段。使用MSRVTT(Xu等,2016)数据集,其中每一视频片段有20个描述句子。结果为测试集检索前1、5、10结果准确性召回率(R@1/5/10)和中位数排名(median rank, MdR)。
视频问答:给定一段视频,回答相关问题,含填空题和多项选择题。使用MSRVTT-QA(Xu等,2017)数据集,结果为测试集多项选择题回答准确率。
动作分割:给定视频,为每一帧选择一个预定义的步骤分割标签。任务使用Coin(Tang等,2019)数据集,含具有明确步骤的日常任务视频片段,每一片段平均标注3.91个步骤,共778个步骤标签,视频无文本描述,结果为帧级标签预测准确率。
步骤定位:对于给定视频,首先定义有序步骤列表,每一步骤通过短文本进行描述,任务为将视频每一帧与步骤匹配。使用CrossTask(Zhukov等,2019)数据集,含83类不同任务。对比结果为召回率。
动作识别:给定视频片段,对其中人物动作所属类别进行分类,动作类别存储于既定标签字典。任务使用数据集为HMDB51(Kuehne等,2011)和UCF101(Soomro等,2012),HMDB51含51类动作,7 000个视频,UCF101含101类动作,13 320个视频。结果为准确率。
视觉语言多模态预训练作为前沿研究,尽管在下游视觉语言交叉任务上已经有了不错的表现,但在未来工作中还需考虑以下几个方向:
1)训练数据域的差异。预训练数据集与下游任务数据集之间存在数据域的差异,部分工作表明(Zhou等,2021):与预训练数据集的域相一致的下游任务数据集可以显著提升任务表现,而数据域的差异是造成模型在不同任务之间迁移时性能下降的重要原因。HERO(Li等,2020b)指出,不能通过增加微调过程的数据规模,来缩小下游任务数据与预训练数据的域差异所造成的影响。MERLOT(Zellers等,2021)使用较为多样的预训练数据,增大了数据域的分布,在一定程度上提升了模型的性能,但也增加了训练消耗。因此,如何提升预训练数据集的质量和多样性是今后预训练任务的重要课题。
2)知识驱动的预训练模型。预训练模型的本质是通过参数量极大的神经网络对大规模训练数据进行拟合,以学习潜在的通用知识,在此过程中扩大数据规模可以带来预训练性能的提升,但会增加计算资源和能耗的消耗,因此一味通过增加数据和训练量换取性能的思路是难以持续的。对于输入的图文、视频等多模态信息,存在着大量隐含的外部常识信息可以用于更快速地引导模型对于事件内容的挖掘(Chen等,2021),因此探索如何通过知识驱动的方式建立具有广泛知识来源的模型架构,将知识图谱等结构化知识注入模型,探索轻量化的网络结构,从而增加模型的训练效率和可解释性,是预训练模型的具有前景的方向。
3)预训练模型的评价指标。现有的视觉语言预训练模型大多在少数几个下游数据集上进行效果的实验验证,难以确切判断在其他数据集上的有效性,而真正通用的预训练系统应该在广泛的下游任务、数据域和数据集上进行推广,这就需要建立较为通用的预训练评价指标,来有效评价预训练效果,并指出模型是否易于在不同任务和数据之间进行迁移。VALUE(Li等,2021a)作为一个视频语言预训练评价基准,覆盖了视频、文本和音频输入,包含了视频检索、视觉问答和字幕匹配任务的11个数据集,根据不同难度的任务的元平均得分(meta-average score)度量预训练模型的性能。但这类工作目前正处于起步阶段,相关的研究也得到研究者重点关注。
4)探索多样的数据来源。视频中的音频包含了丰富的信息,当前视频预训练中常使用ASR方法将音频转换为文本,在此过程中部分原有信息受到损失,因此探索包含音频的预训练模型是一个可取的方向。目前的多模态预训练数据来源以英文图文和视频为主,进行多语言学习的预训练工作较少,将模型在不同语言间进行迁移还需要继续研究。此外,探索从结构化的多模态数据中进行更细粒度的预训练工作(Zellers等,2021),如从图表中进行目标推理的训练也是可以探索的方向。
5)预训练模型的社会偏见和安全性。由于大规模数据集在来源上涉及范围广泛,难以逐一排查具体信息,数据中难以避免地存在部分社会偏见以及错误知识,而通过预训练模型学习到这些不良内容,其生成的结果会进一步增加这类内容所造成的影响,引发更大的社会问题(Dixon,2008)。因此在获取数据时如何对存在的数据隐私,以及涉及国家、种族和性别公平性等问题进行考量,通过算法对选取的预训练数据内容进行过滤,在社会安全、伦理等方面尤其重要。
视觉和语言在人类学习视觉实体与抽象概念的过程中扮演着重要的角色,本文对视觉和语言多模态预训练领域自2019年以来的模型与方法,基于视觉来源从图像—文本与视频—文本两大方向进行综述,并进一步基于模型结构分别介绍各具体模型的特点与研究贡献。此外,还介绍了常用视觉语言多模态预训练模型数据集、预训练任务设定以及各模型在主要下游任务上的表现。最后对该领域的问题与挑战进行了总结并提出未来研究方向。希望通过本文让读者了解领域工作前沿,以启发进而做出更有价值的多模态预训练工作。
猜你喜欢 模态图像特征 联合仿真在某车型LGF/PP尾门模态仿真上的应用汽车实用技术(2022年10期)2022-06-09EASY-EV通用底盘模态试验汽车实用技术(2022年9期)2022-05-20抓特征解方程组初中生世界·七年级(2019年5期)2019-06-22不忠诚的四个特征当代陕西(2019年10期)2019-06-03A、B两点漂流记初中生世界·九年级(2018年12期)2018-12-22模态可精确化方向的含糊性研究成长·读写月刊(2018年8期)2018-08-30名人语录的极简图像表达读者(2015年9期)2015-05-04一次函数图像与性质的重难点讲析初中生世界·八年级(2014年2期)2014-03-15基于CAE的模态综合法误差分析计算机辅助工程(2012年5期)2012-11-21趣味数独等4则意林(2011年10期)2011-05-14







